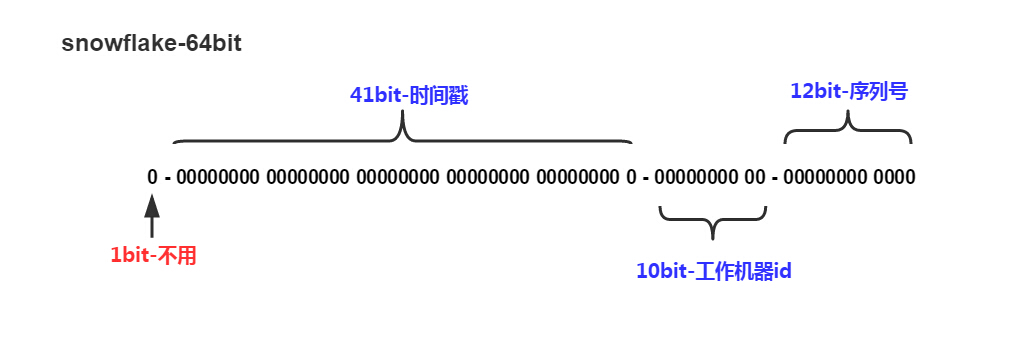
原论文
Dean, Jeffrey, and Sanjay Ghemawat. “MapReduce: simplified data processing on large clusters.” Communications of the ACM 51.1 (2008): 107-113.
前言
Google 三驾马车之一,MIT 6.824 first day 的 preparation task。
Abstract
MapReduce is a programming model and an associated implementation for processing and generating large data sets. Users specify a map function that processes a key/value pair to generate a set of intermediate key/value pairs, and a reduce function that merges all intermediate values associated with the same intermediate key.
MapReduce 通过 Map 函数对一个基于 k-v 对的数据集进行处理,生成对应的中间数据集,再通过 Reduce 函数对这些中间数据集中具有相同的 key 的 value 进行合并。
关注点
The run-time system takes care of the details of partitioning the input data, scheduling the program’s execution across a set of machines, handling machine failures, and managing the required inter-machine communication.
- 如何分割输入数据。
- 分布式集群的调度。
- 机器的错误处理。
- 集群机器间的通信。
解决问题
The input data is usually large and the computations have to be distributed across hundreds or thousands of machines in order to finish in a reasonable amount of time. The issues of how to parallelize the computation, distribute the data, and handlefailures conspire to obscure the original simple computation with large amounts of complex code to deal with these issues.
输入的数据量巨大,难以在单机下完成,如果想在可接受的时间内完成,需要将计算分给成百上千的机器上。