最近想看看自己的深蹲硬拉时的杠铃轨迹,顺便检测下动作。搜了搜Iron Path可以实现,但是iOS独占,没有Android版本。怎么办?那就自己写一个吧。
用了OpenCV3.2预置的6种Tracker(BOOSTING,MIL,KCF,TLD,MEDIANFLOW,GOTURN),Dlib预置的Tracker,以及CamShift与Template_Match总共9种追踪器实现了杠铃轨迹实时追踪(追踪目标当然不限于杠铃,其他目标也同样可以)。
最后比较了一下以上9种追踪器的追踪效率。
示例


以军神的全蹲为例

自己的渣蹲
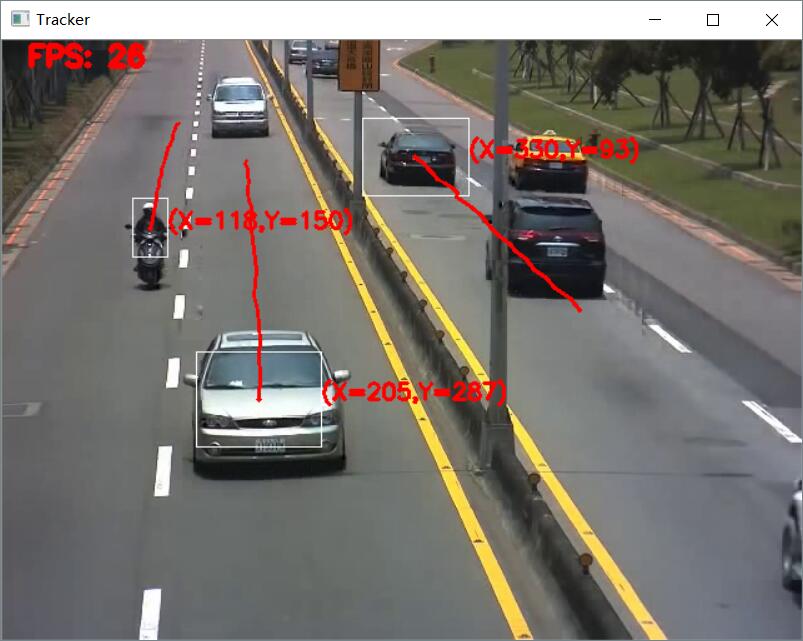
多目标追踪
跟踪器
以下内容来自https://www.learnopencv.com/object-tracking-using-opencv-cpp-python/。
BOOSTING
此跟踪器基于AdaBoost的在线版本 - 基于HAAR级联的面部检测器在内部使用的算法。 这个分类器需要在运行时用对象的正和负例子训练。 由用户提供的初始边界框(或由另一个对象检测算法)作为对象的正例,并且边界框外部的许多图像补片被当作背景。 给定新帧,对先前位置的邻域中的每个像素运行分类器,并记录分类器的得分。 对象的新位置是得分最大的位置。 所以现在我们有一个更积极的例子为分类器。 随着更多的帧进入,分类器用该附加数据更新。
优点:无。 这个算法是十年前出现的了,但我找不到一个很好的理由使用它,特别是当其他高级跟踪器(MIL,KCF)基于类似的原理也可用时。
缺点:跟踪性能平庸。
MIL
此跟踪器在概念上类似于上述的BOOSTING跟踪器。 最大的区别在于,代替仅考虑对象的当前位置作为积极示例,它在当前位置周围的小邻域中查找以生成若干潜在的正例子。你可能认为这是一个坏主意,因为在大多数这些“积极”的例子中,对象不是中心。
在MIL中,你没有指定正和负例子,但是有正和负“包”。 正包中的图像集合并不都是积极的例子。 相反,只有一个图像在积极的包里需要一个积极的例子。在我们的示例中,正包包含以对象的当前位置为中心的补丁,以及在其周围的小邻域中的补丁。 即使被跟踪对象的当前位置不准确,当来自当前位置的邻域的样本被放入正包中时,很有可能这个包包含至少一个图像,其中对象被良好地置于居中。
优点:性能相当不错。它不像BOOSTING跟踪器那样漂移,它在部分遮挡下合理地工作。如果你使用OpenCV 3.0,这可能是你可用的最好的跟踪。 但是如果你使用更高版本,考虑KCF。
缺点:跟踪失败报告不可靠。不能从完全闭塞恢复。
KCF
KFC代表内核化相关滤波器。 这个跟踪器建立在前两个跟踪器提出的想法。该跟踪器利用了这样的事实,即在MIL跟踪器中使用的多个正样本具有大的重叠区域。这种重叠的数据导致一些良好的数学特性,利用这个跟踪器,使跟踪更快,同时更准确。
优点:准确度和速度都比MIL更好,它报告跟踪失败比BOOSTING和MIL更好。
缺点:不能从完全闭塞恢复。
TLD
TLD代表跟踪,学习和检测。顾名思义,该跟踪器将长期跟踪任务分解为三个组件-(短期)跟踪,学习和检测。从作者的论文,“跟踪器跟踪对象从一帧到帧。检测器定位到目前为止观察到的所有外观,并在必要时校正跟踪器。学习估计检测器的错误并更新它以避免未来的这些错误。“这个跟踪器的输出往往会跳一下。例如,如果你正在跟踪行人,并且场景中还有其他行人,则该跟踪器有时可以临时跟踪与您要跟踪的行人不同的行人。在积极的一面,这条轨道似乎在更大的规模,运动和遮挡下跟踪物体。如果你有一个视频序列,其中的对象隐藏在另一个对象后面,这个跟踪器可能是一个不错的选择。
优点:在多个帧的遮挡下工作最好。此外,跟踪最佳的规模变化。
缺点:很多误报,使它几乎不可用。
MEDIANFLOW
在内部,该跟踪器在时间上向前和向后方向上跟踪对象,并且测量这两个轨迹之间的差异。最小化该ForwardBackward错误使它们能够可靠地检测跟踪失败并在视频序列中选择可靠的轨迹。在我的测试中,我发现这个跟踪器在运动是可预测和小规模的时候效果最好。与其他跟踪器不同,即使跟踪明显失败,该跟踪器知道跟踪失败的时间。
优点:优秀的跟踪失败报告。 当运动是可预测的并且没有遮挡时工作得很好。
缺点:在大规模运动下失败。
GOTURN
在跟踪器类中的所有跟踪算法中,这是基于卷积神经网络(CNN)的唯一一种。它也是唯一一个使用离线训练模型,因为它比其他跟踪器更快。从OpenCV文档,我们知道它“对视点变化,照明变化和变形是强大的”。但它不能很好地处理遮挡。
Bug警告:在使用Goturn时OpenCV 3.2会报错,无法实现。(个人实现的确如此)
Dlib_Tracker
This is a tool for tracking moving objects in a video stream. You give it the bounding box of an object in the first frame and it attempts to track the object in the box from frame to frame.
This tool is an implementation of the method described in the following paper:
Danelljan, Martin, et al. “Accurate scale estimation for robust visual tracking.” Proceedings of the British Machine Vision Conference BMVC. 2014.引自Dlib官方文档: http://dlib.net/imaging.html#correlation_tracker
Dlib内置的追踪器背后算法来自于2014年Martin Danelljan于BMCV发表的一篇paper,”Accurate Scale Estimation for Robust Visual Tracking”,论文中主要描述了一种在视觉跟踪中精准的尺度估计的方法,基于此尺度估计方法提出了DSST(Discriminatiive Scale Space Tracker)算法。Martin Danelljan也凭此算法拿下2014 VOT(Visual-Object-Tracking) Challenge的冠军,VOT Challenge是视觉跟踪领域的国际顶级赛事。看了下历年数据,2015年深度学习开始冲击tracking领域,此后赛事的冠军再也没有使用纯传统算法的,最近的2017年冠军使用的则是传统滤波结合深度学习的混合模型,可谓历史潮流浩浩汤汤了。
DSST是一种基于相关滤波的跟踪算法,其最初的代表作可以追溯到2010年CVPR的”Visual object tracking using adaptive correlation filters”,这篇paper提出了一种MOSSE correlation filter,并将其应用于视觉跟踪当中,取得了较好的效果。
MOSSE(Visual Object Tracking using Adaptive Correlation Filters )在求解滤波器时,其输入项是图像本身(灰度图),也就是图像的灰度特征。对于灰度特征,其特征较为简单,不能很好的描述目标的纹理、边缘等形状信息,因此DSST的作者将灰度特征替换为在跟踪和识别领域较为常用的HOG特征。
DSST作者将跟踪分为两个部分,位置变化(translation)和尺度变化(scale estimation)。在跟踪的实现过程中,作者定义了两个correlation filter,一个滤波器(translation filter)专门用于确定新的目标所处的位置,另一个滤波器(scale filter)专门用于尺度评估。
在translation filter方面,作者的方法与MOSSE的方法是一样的,只不过其获取最佳模板H的准则有了些许变化。根据translation filter可以获取当前帧目标所处的位置,然后在当前目标位置获取不同尺度的候选框,经过scale filter之后,确定新的目标尺度。
CamShift
实现了前面几个Tracker后,已经能满足我最初的杠铃轨迹追踪需求。但是在追踪车辆时,遇到了一个问题。当框选完车辆后,因为车辆从远到近驶来,车辆的大小是由小变大的,但是追踪框只能保持最初框选的大小。当车辆由近处驶向远处时,因为车辆越来越小,追踪器很容易失去目标。为了解决这个问题,引入CamShift算法。
CamShift算法的全称是”Continuously Adaptive Mean-SHIFT”,即:连续自适应的MeanShift算法。其基本思想是对视频序列的所有图像帧都作MeanShift运算,并将上一帧的结果(即搜索窗口的中心位置和窗口大小)作为下一帧MeanShift算法的搜索窗口的初始值,如此迭代下去。
简单点说,MeanShift是针对单张图片寻找最优迭代结果,而CamShift则是针对视频序列来处理,并对该序列中的每一帧图片都调用MeanShift来寻找最优迭代结果。正是由于CamShift针对一个视频序列进行处理,从而保证其可以不断调整窗口的大小,如此一来,当目标的大小发生变化的时候,该算法就可以自适应地调整目标区域继续跟踪。
在OpenCV给出的CamShift Demo当中,是通过计算目标在HSV空间下的H分量直方图,通过直方图反向投影得到目标像素的概率分布,然后通过调用OpenCV的CAMSHIFT算法,自动跟踪并调整目标窗口的中心位置与大小。该算法对于简单背景下的单目标跟踪效果较好,但如果被跟踪目标与背景颜色或周围其它目标颜色比较接近,则跟踪效果较差。另外,由于采用颜色特征,所以它对被跟踪目标的形状变化有一定的抵抗能力。


追踪框会自适应缩放
Template Match
Template Match应该是最简单的追踪算法了,原理就是遍历图像中的每一个可能的位置,比较各处与模板是否“相似”,当相似度足够高时,就认为找到了我们的目标。
首先确定一个模板T,在视频目标追踪中模板即为我们最初选定的追踪目标,然后用模板在当前帧的图像I上滑动,一次移动一个像素(从左往右,从上往下),在每一个位置,都进行一次度量计算来表明它是 “好” 或 “坏” 地与那个位置匹配,或者说块图像和原图像的特定区域有多么相似。对于T的每个位置超过I,则存储在该度量结果矩阵R,R中的每个位置(x,y)都包含匹配度量。OpenCV中的TM_CCORR_NORMED方法将返回矩阵R中匹配值最高(或最小,这取决于你使用何种相似度方法)的区域,该区域的长宽和模板图像的一致。
OpenCV 提供了6种计算两幅图像相似度的方法:
- 差值平方和匹配 CV_TM_SQDIFF
- 标准化差值平方和匹配 CV_TM_SQDIFF_NORMED
- 相关匹配 CV_TM_CCORR
- 标准相关匹配 CV_TM_CCORR_NORMED
- 相关匹配 CV_TM_CCOEFF
- 标准相关匹配 CV_TM_CCOEFF_NORMED
注意,平方差匹配CV_TM_SQDIFF与标准平方差匹配TM_SQDIFF_NORMED最佳匹配为最小值 0,匹配值越大匹配越差,其余则相反。
缺点:OpenCV中的模板匹配使用的是灰度匹配,灰度匹配的特长就是精度高,因为是一个个像素点在比较。但缺点就是计算时间长,因为要计算的点多,一个个比较花费很长时间。
此外,当图像中出现了其他与模板相似的目标时,很可能会匹配到错误的目标。
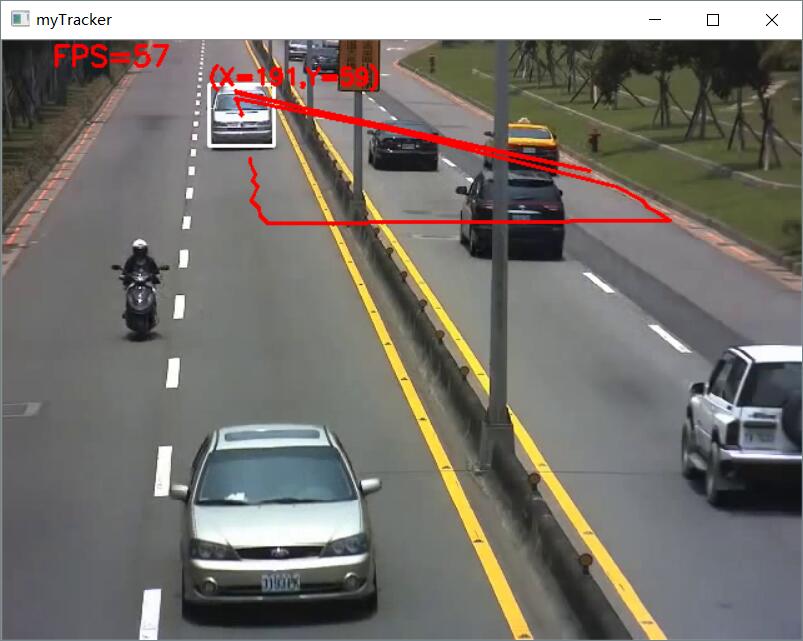
选定前面的白色小车为模板,但却追踪到了后面的白色小车,因为前后两辆白色小车十分相似
Lukas-Kanade 光流法
很可惜因为能力有限最终没有将LK光流法加进来,只是稍微了解了一下这个算法。




摘自Python计算机视觉编程 10.4追踪

LK光流法的一个Demo
比较结果
以单目标追踪为例:
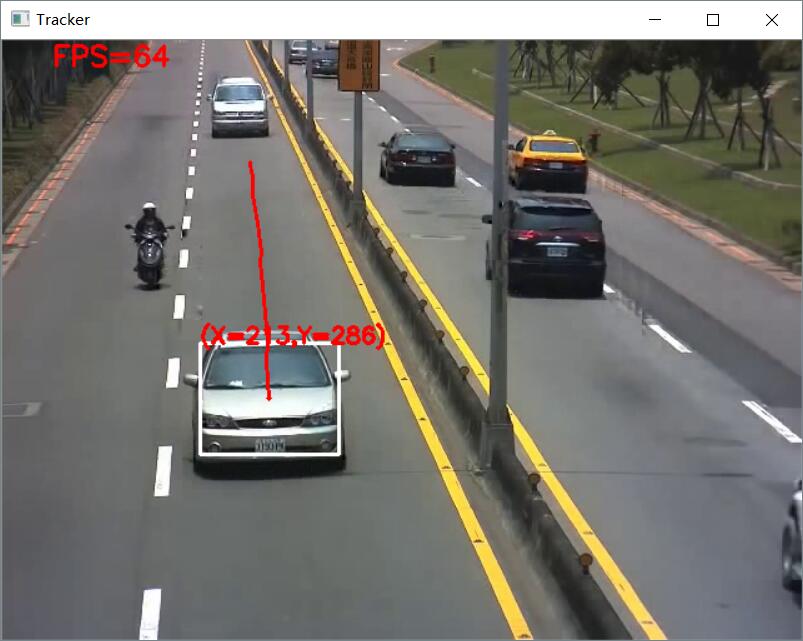


可见,KCF、CamShift、MEDIANFLOW、Dlib_Tracker表现的都不错,GOTURN报错跑不通,暂时还没找到原因,Template_Matching追踪到后面同样颜色的小车,这两个判定为追踪失败。但KCF、CamShift、MEDIANFLOW帧数上下波动幅度很大,不稳定,Dlib则十分稳定。实际使用中Dlib已经足以满足一般性的需求。
使用
鼠标左键拖选一个追踪的目标,然后按 Enter 开始追踪,结束追踪只需按Esc。
代码
1 | # -*- coding: utf-8 -*- |