原论文
Q. He, X. Zhu, D. Li, et al., “Cost-effective Big Data Mining in the Cloud: A Case Study with K-means,” in Cloud Computing (CLOUD), 2017 IEEE 10th International Conference on, 2017, pp. 74-81. (EI: 20174404313852)
摘要
在某些大数据挖掘情景下,100%的准确率是没有必要的,通常采用的是比100%准确率成本低得多的准确率,例如99%或99.9%。事实上,在某些例如天气预测和交通堵塞预测这类预测情景下,达到100%的准确率也是不可能的。所以在一个合理的准确度停下,可以达到更好的成本效益。这对于中小企业来说,是十分重要的。
在以K-means算法为例的聚类任务中,论文发现达到99%的聚类准确度只需要花费达到100%准确度的0.32%-46.17%成本。
相关工作
Mehrotra等人在NASA的高性能机群计算与Iousp等人在多任务计算的研究中得出了相似的结论,即公有云的性能对于高性能计算应用来说还不够高。Berriman等人通过比较亚马逊EC2云服务器与美国国家超级计算机中心的Abe高性能集群发现,亚马逊EC2云能为处理器与内存受限的应用提供比I/O受限应用更高的性能与价值。Carlyle等人在普渡大学的”community cluster”计划中,比较了传统HPC与亚马逊EC2云的高性能计算成本,他们的研究发现当满足以下三个条件时,内部集群更具成本效益:1.有足够的需求充分利用机群 2.有能有维护IT基础设施的IT部门 3.以计算网络研究为优先。Deelman等人发现在云服务器中运行计算密集型应用比数据密集型应用更具成本效益。 Gupta等人的实验表明目前云计算并不能完全替代超级计算机,但能有效的与之互补。
算法
采用K-means中的Lloyd算法
评价指标
采用Rand index(兰德指数)衡量K-means聚类后的结果与原数据集的相似度,范围0-1
付费模式
采用亚马逊云的按需付费模式(时间),通过计算每次K-means的过程耗时即可得出费用。运行K-means可能会产生其他成本,比如要传输聚类的数据集,但论文研究只关注计算时间成本。
数据集
实验中采用了两种数据集:
- 高斯数据集:这是利用基于高斯分布生成的数据集。首先随机产生72个点,然后以这每个点基于标准差=0.05的高斯分布生成13,889个二维数据点。在这个32Mb的数据集中共有1,000,008个二维数据点。
- 道路网络数据集:这是一个UCI机器学习与智能系统提供的公共数据集,覆盖了丹麦North Jutland中185x135km2的区域。这个20Mb的数据集中共有434,8743个三维数据点。
实验结果
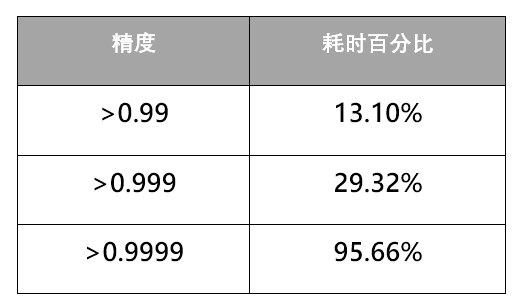
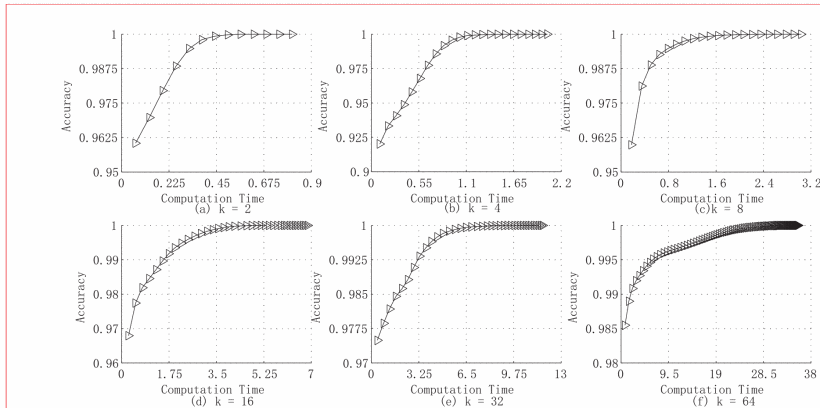 图1:高斯数据集下K-means的准确率与耗时
图1:高斯数据集下K-means的准确率与耗时
上图显示k-means算法首先进行相对少量的迭代以达到一定足够高的准确率,然后进行了大量迭代达到100%的准确率,这就是长尾效应。长尾现象表明k-means算法在中后期消耗了大部分计算时间。例如当k = 64时,k-means算法需要3次迭代(2.27秒)达到0.99的精确度,即99%,然后继续进行84次迭代(33.20秒)才达到100%的准确率。
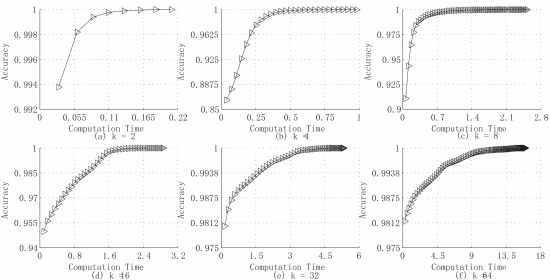 图2:道路网络数据集下K-means的准确率与耗时
图2:道路网络数据集下K-means的准确率与耗时
道路网络数据集也展示了类似的长尾效应,这在真实数据中证实了在高斯数据集中的发现,表面了在现实世界的大数据挖掘情景中,成本效益具有极高的意义。
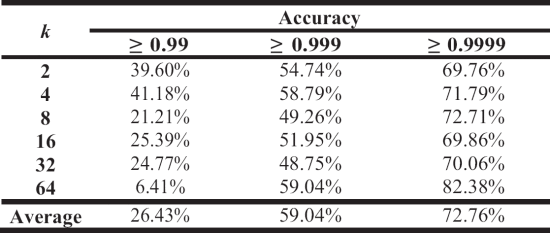 表1:多个k值下计算耗时百分比 (高斯数据集)
表1:多个k值下计算耗时百分比 (高斯数据集)
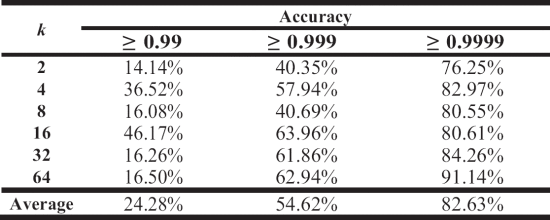 表2:多个k值下计算耗时百分比 (道路网络数据集)
表2:多个k值下计算耗时百分比 (道路网络数据集)
从上述两个表格不难发现,为了从准确率99%达到接近100%,这1%的准确率耗费了大量的计算时间。这再次表明,在牺牲极少的准确率下,在适合的时间点停下迭代算法,可以为用户省下大量的费用。
长尾效应
通过其他实验,论文还发现选择不好的初始中心点导致了十分明显的长尾效应。
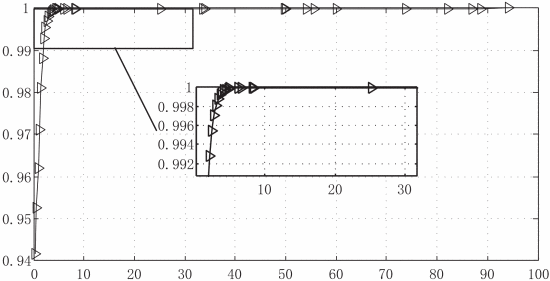
与图1所不同,图3的长尾效应要明显得多。内部图放大了外部图中准确率超过0.99的部分。k=20下K-means用了总计算时间的2.23%,达到0.99的准确率(精确值为0.9927)。为了达到0.999的准确率和0.9999的准确率,耗时分别只占总计算时间的3.79%和6.50%。这种情况下比较极端,即最后为了增加0.0001的准确率,耗费了93.50%的总时间,这显然是十分荒谬的。
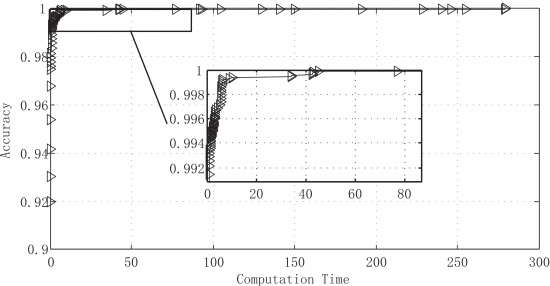
图4中还发现了算法对长尾部分上每次迭代所耗费的计算时间高度不均,曲线有明显波动,有些耗时比其他的要长得多。这是因为算法不得不在每次迭代中改变中心点,这种情况在选择较好的初始中心点时较少发生。
个人认为这是因为K-means对初始聚类中心选择敏感,随机选择初始中心点显然是不合理的,应该选择距离数据点最远的k个点。
结论与展望
实验结果证实了大数据挖掘在云计算中的成本效益的重要性。在实验中,K-means算法仅占总计算时间的0.32%-46.17%,就可以达到99%的准确度。这可以节省下99.68%的费用成本,仅仅损失了1%的准确率。未来可以通过其他内部准确度评价指标和其他数据挖掘算法,进一步探索云计算下大数据挖掘的成本效益问题。
多变量线性回归下的实验
下面是自己用线性回归做的一个很简单的实验验证
算法
采用梯度下降法进行线性回归
评价指标
采用均方误差(mean-square error, MSE)
其中:
m:训练样本的个数;
hθ(x):用参数θ和x预测出来的y值
y:原训练样本中的y值
数据集
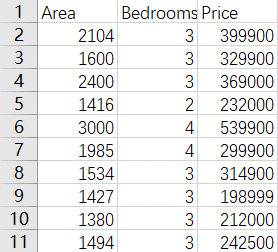
采用的数据集格式如下图所示,共有47个样本(面积单位为平方英尺,价格单位为美元):
实验结果
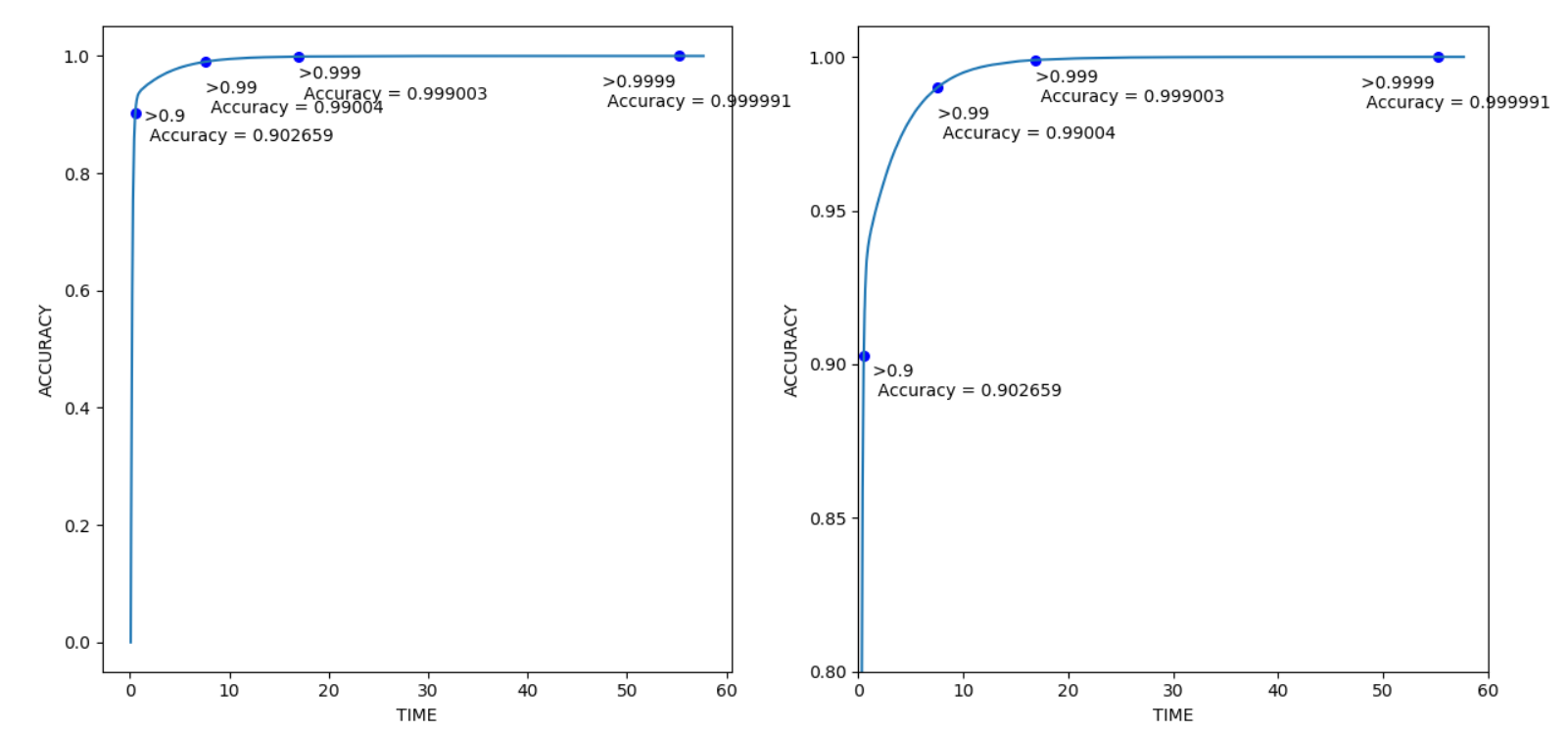
总结如下表所示,可以看出,在这个线性回归的案例中,程序用了总计算时间的13.10%和29.32%,达到了0.99与0.999的准确率,最后为了提高0.0001的准确率,耗费了93.50%的总时间。这个简单的实验也有力印证了在线性回归的最优化中同样存在着长尾效应。