Flask中的上下文与出入栈
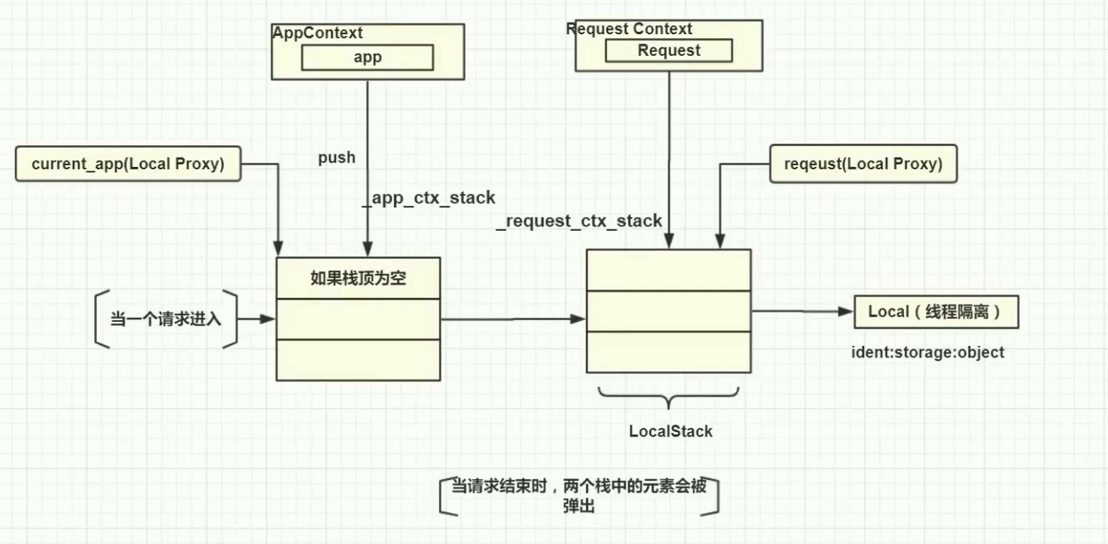
- 当一个请求进入Flask框架,首先会实例化一个
Request Context,这个上下文封装了请求的信息在Request中,并将这个上下文推入到一个栈(_request_ctx_stack/_app_ctx_strack)的结构中 RequestContext在入_request_ctx_stack之前,首先会检查全局变量_app_ctx_strack是否为空,如果为空,则会把一个AppContext的对象入栈,然后再将这个请求入栈到全局变量_request_ctx_stack中current_app和request对象都是永远指向_app_ctx_strack/_request_ctx_stack的栈顶元素,也就是分别指向了两个上下文,如果这两个值是空的,那么LocalProxy就会出现unbound的状态- 当请求结束的时候,这个请求会pop出栈
简单来说,每一个请求到来之后,flask都会为它新建一个RequestContext对象,并且将这个对象push进全局变量_request_ctx_stack中,在push前还要检查_app_ctx_stack,如果_app_ctx_stack的栈顶元素不存在或是与当前的应用不一致,则首先push appcontext到_app_ctx_stack中,再push requestcontext。
举一个例子,app1._request_context()时,会将app1对应的context压栈,当前活跃app context是app1的,所以url_for使用的是app1的context,当with app2._request_context()时,会将app2对应的context压栈,当前活跃app context是app2的,当请求结束后,将弹出app2的context,此时活跃的为app1。
AppContext、RequestContext、Flask与Request的意义
- Flask:核心对象,核心对象里承载了各种各样的功能,比如保存配置信息,再比如注册路由试图函数等
- AppContext:对
Flask的封装,并且增加了一些额外的参数 - Request:保存了请求信息,比如
url的参数,url的全路径等信息 - RequestContext:对
Request的封装
线程隔离
werkzeug中的Local通过dict来实现线程隔离,以线程id号为key。而无论是_app_ctx_stack还是_request_ctx_stack都是一个LocalStack()对象,这是werkzeug中的一个封装了Local的对象,实质上就是一个线程隔离的栈,下面的源码很清楚的说明了这一点。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36class Local(object):
__slots__ = ('__storage__', '__ident_func__')
def __init__(self):
object.__setattr__(self, '__storage__', {}) #实质就是一个字典
object.__setattr__(self, '__ident_func__', get_ident)
def __iter__(self):
return iter(self.__storage__.items())
def __call__(self, proxy):
"""Create a proxy for a name."""
return LocalProxy(self, proxy)
def __release_local__(self):
self.__storage__.pop(self.__ident_func__(), None)
def __getattr__(self, name):
try:
return self.__storage__[self.__ident_func__()][name]
except KeyError:
raise AttributeError(name)
def __setattr__(self, name, value):
ident = self.__ident_func__() #__ident_func__()方法可以取到线程id号
storage = self.__storage__
try:
storage[ident][name] = value #将ident,即取到的线程id号作为key
except KeyError:
storage[ident] = {name: value}
def __delattr__(self, name):
try:
del self.__storage__[self.__ident_func__()][name]
except KeyError:
raise AttributeError(name)
线程隔离的意义就在于使当前线程能够正确引用到自己所创建的对象,而不是引用到其他线程所创建的对象
EndPoint
首先,举一个最简单的例子:1
2
3@web.route('/hello')
def hello():
return 'hello'
这是一个十分典型的由URL映射到视图函数方法。虽然Flask的路由表面上是使用了route这个装饰器,实际上内部也是调用app对象中的add_url_rule方法来实现。下面的代码同上面的是等价的。1
2
3def hello():
return 'hello'
app.add_url_rule('/hello', 'hello', hello)
实际上,Flask并不是直接由URL映射至视图函数上,Flask在这过程中隐藏了一些细节。真正的过程是这样的:URL-->endpoint-->viewfunction。app.add_url_rule('/hello', 'hello', hello)中最后的hello参数即是endpoint。下面看一下Flask的源码:1
2
3
4
5
6
7self.url_map.add(rule)
if view_func is not None:
old_func = self.view_functions.get(endpoint)
if old_func is not None and old_func != view_func:
raise AssertionError('View function mapping is overwriting an '
'existing endpoint function: %s' % endpoint)
self.view_functions[endpoint] = view_func
注意到最后一段代码,Flask是通过endpoint作为key来找到view_func的。当Flask的核心对象app初始化前,Flask都向view_functions添加好endpoint-view——func的key-value对,所以view_functions的实质就是一个字典。
那么,Flask为何要”多此一举”呢?答案就在于反向构建URL。如果没有endpoint,就无法通过视图函数来反向查找到URL地址时。这个刚好过程和上面相反:viewfunction-->endpoint-->URL。1
2
3@app.route('/')
def index():
print url_for('hello', name='user') #会跳转到/user/hello
在实际中,当需要在一个视图中跳转到另一个视图中的时候,通常使用的是url_for(),而不是html地址。
再举一个多蓝图的例子可以更好的理解endpoint的作用:1
2
3
4
5#user.py
user = Blueprint('user', __name__)
@user.route('/hello')
def hello():
return 'Hello,User!'
1 | #admin.py |
问题来了,如何找到不同用户所需要的hello页面呢?答案是对于分布在不同文件下的不同view函数,可以通过url_for('admin.hello')或url_for('user.hello')来跳转。对于这两个view来说,双方都是可见的,Flask通过url_for()与endopoint来让我们用这种简洁而优雅的方式来完成页面跳转。同时,endpoint使得我们可以随意改变应用中的URL地址,却不用修改与之关联的资源的代码。真是太方便啦~
View_Models的意义
对Models层的数据进行裁剪、修饰、合并,返回给View层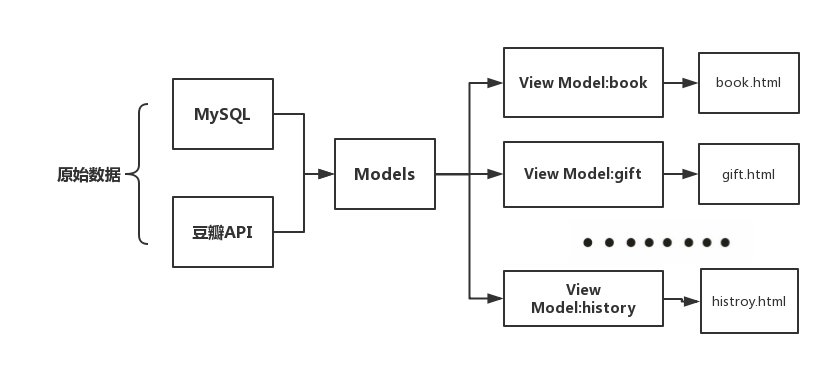
SQLAlchemy报错:sqlalchemy.exc.InternalError
1 | sqlalchemy.exc.InternalError: (cymysql.err.InternalError) (1055, "Expression #1 of SELECT list is not in GROUP BY clause and contains nonaggregated column 'bookcrossing.gift.create_time' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by") [SQL: 'SELECT DISTINCT gift.create_time AS gift_create_time, gift.status AS gift_status, gift.id AS gift_id, gift.uid AS gift_uid, gift.isbn AS gift_isbn, gift.launched AS gift_launched \nFROM gift \nWHERE gift.launched = false AND gift.status = %s GROUP BY gift.isbn ORDER BY gift.create_time DESC \n LIMIT %s'] [parameters: (1, 30)] (Background on this error at: http://sqlalche.me/e/2j85) |
解决办法:my.conf中关闭MySQL严格模式1
2[mysqld]
sql-mode="STRICT_TRANS_TABLES,NO_ENGINE_SUBSTITUTION"
服务器上无法发送Email
解决办法:因为VPS服务商封了25端口,开启SSL用465端口即可(126邮箱)