前言
实现简单而有效的推荐系统其实并不复杂,本文介绍了几种常见的推荐系统技术,包括基于用户/物品的协同过滤、基于内容与基于知识的推荐系统,以及这几种技术的优缺点,并使用MovieLens数据集构造了一个十分简单的基于物品的推荐系统。
文章为个人兴趣译制,原文链接请点击这里。译文已投稿至伯乐在线,感谢原作者的奉献,感谢”小米云豆粥”的校对。
推荐系统概述
“Many receive advice, only the wise profit from it.” – Harper Lee
“聆忠言者众,惟智者受益。” — 哈珀·李
我们中的许多人把推荐系统视为一种神秘的存在,因为他们觉得推荐系统似乎知道我们的想法是什么。想想看Netflix的推荐引擎,它向我们推荐电影,还有亚马逊,它向我们推荐该买什么样的商品。推荐系统从早期发展到现在,已经得到了很大的改进和完善,以不断地提高用户体验。尽管推荐系统中许多都是非常复杂的系统,但其背后的基本思想依然十分简单。
推荐系统是什么?
推荐系统是信息过滤系统的一个子类,它根据用户的偏好和行为,来向用户呈现他(或她)可能感兴趣的物品。推荐系统会尝试去预测你对一个物品的喜好,以此向你推荐一个你很有可能会喜欢的物品。
如何构建一个推荐系统?
虽然现在已经有很多种技术来建立一个推荐系统了,但我选择向你们介绍其中最简单,也是最常用的三种。他们是:一,协同过滤;二,基于内容的推荐系统;三,基于知识的推荐系统。我会解释前面的每个系统相关的弱点,潜在的缺陷,以及如何去避免它们。最后,我在文章末尾为你们准备了一个推荐系统的完整实现。
协同过滤
协同过滤,作为第一种被用在推荐系统上的技术,至今仍是最简单且最有效的。协同过滤的过程分为这三步:一开始,收集用户信息,然后以此生成矩阵来计算用户关联,最后作出高可信度的推荐。这种技术分为两大类:一种基于用户,另一种则是基于组成环境的物品。
基于用户的协同过滤
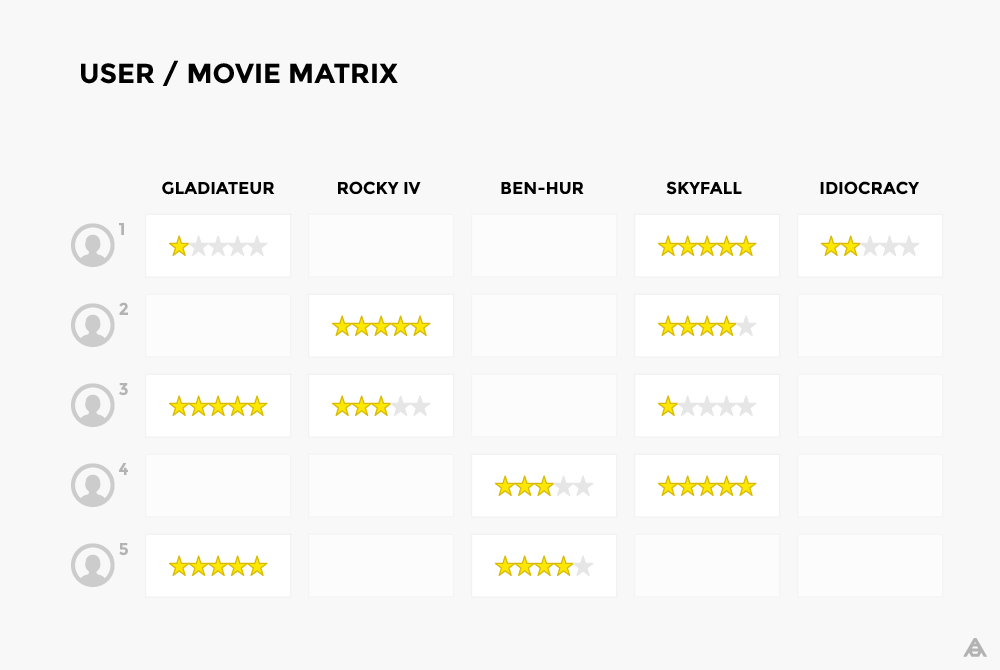
基于用户的协同过滤背后的思想是寻找与我们的目标用户具有相似品味的用户。如果Jean-Pierre和Jason曾对几部电影给出了相似的评分,那么我们认为他们就是相似的用户,接着我们就可以使用Jean Pierre的评分来预测Jason的未知评分。例如,如果Jean-Pierre喜欢星球大战3:绝地武士归来和星球大战5:帝国反击战,Jason也喜欢绝地武士归来,那么帝国反击战对Jason来说是就是一个很好的推荐。一般来说,你只需要一小部分与Jason相似的用户来预测他的评价。

在下表中,每行代表一个用户,每列代表一部电影,只需简单地查找这个矩阵中行之间的相似度,就可以找到相似的用户了。
然而,基于用户的协同过滤在实现中存在一些以下问题:
- 用户偏好会随时间的推移而改变,推荐系统生成的许多推荐可能会随之变得过时。
- 用户的数量越多,生成推荐的时间就越长。
- 基于用户会导致对托攻击敏感,这种攻击方法是指恶意人员通过绕过推荐系统,使得特定物品的排名高于其他物品。
(托攻击即Shilling Attack,是一种针对协同过滤根据近邻偏好产生推荐的特点,恶意注入伪造的用户模型,推高或打压目标排名,从而达到改变推荐系统结果的攻击方式)
基于物品的协同过滤
基于物品的协同过滤过程很简单。两个物品的相似性基于用户给出的评分来算出。让我们回到Jean-Pierre与Jason的例子,他们两人都喜欢“绝地武士归来”和“帝国反击战”。 因此,我们可以推断,喜欢第一部电影的大多数用户也可能会喜欢第二部电影。所以,对于喜欢“绝地武士归来”的第三个人Larry来说,”帝国反击战“的推荐将是有意义的。
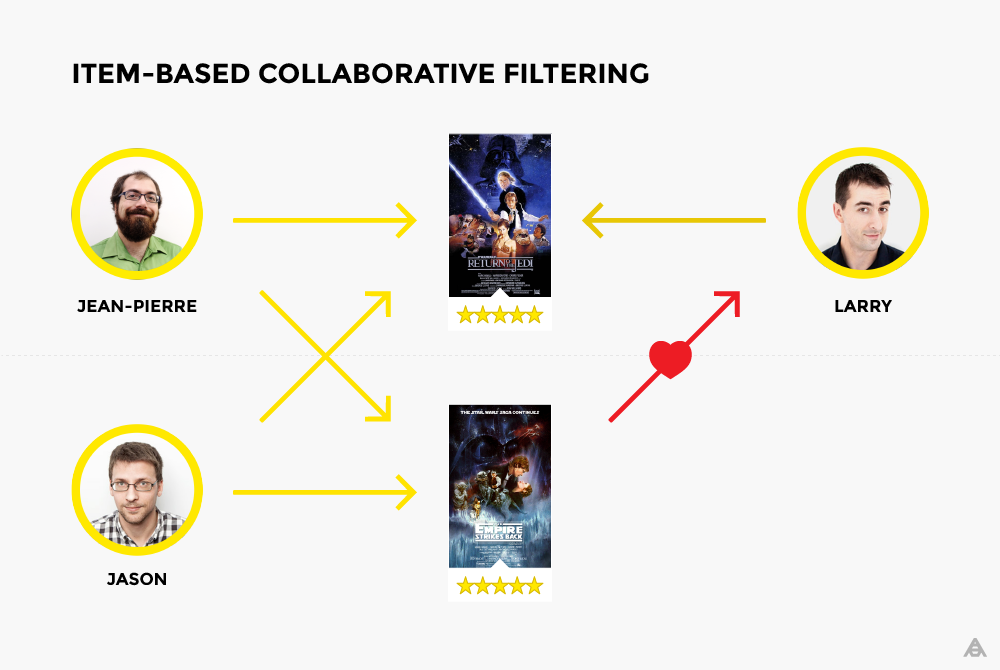
所以,这里的相似度是根据列而不是行来计算的(与上面的用户-电影矩阵中所见的不同)。基于物品的协同过滤常常受到青睐,因为它没有任何基于用户的协同过滤的缺点。首先,系统中的物品(在这个例子中物品就是电影)不会随着时间的推移而改变,所以推荐会越来越具有关联性。此外,通常推荐系统中的物品都会比用户少,这减少了推荐的处理时间。最后,考虑到没有用户能够改变系统中的物品,这种系统要更难于被欺骗或攻击。
基于内容的推荐系统
在基于内容的推荐系统中,元素的描述性属性被用来构成推荐。“内容Content”一词指的就是这些描述。举个例子,根据Sophie的听歌历史,推荐系统注意到她似乎喜欢乡村音乐。因此,系统可以推荐相同或相似类型的歌曲。更复杂的推荐系统能够发现多个属性之间的关系,从而产生更高质量的推荐。例如,音乐基因组计划(Music Genome Project)根据450个不同的属性将数据库中的每支歌曲进行分类。该项目为Pandor的歌曲推荐提供技术支持。(Pandor提供在线音乐流媒体服务,类似Spolify)
基于知识的推荐系统
基于知识的推荐系统在物品购买频率很低的情况下特别适用。例如房屋、汽车、金融服务甚至是昂贵的奢侈品。在这种情况下,推荐的过程中常常缺乏商品的评价。基于知识的推荐系统不使用评价来作出推荐。相反,推荐过程是基于顾客的需求和商品描述之间的相似度,或是对特定用户的需求使用约束来进行的。这使得这种类型的系统是独一无二的,因为它允许顾客明确地指定他们想要什么。关于约束,当应用时,它们大多是由该领域的专家实施的,这些专家从一开始就知道该如何实施这些约束。例如,当用户明确指出在一个特定的价格范围内寻找一个家庭住宅时,系统必须考虑到这个用户规定的约束。
推荐系统中的冷启动问题
推荐系统中的主要问题之一是最初可用的评价数量相对较小。当新用户还没有给电影打分,或者一部新的电影被添加到系统中时,我们该怎么做呢?在这种情况下,应用传统的协同过滤模型会更加困难。尽管基于内容和基于知识的推荐算法在面临冷启动问题时比协同过滤更具有鲁棒性,但基于内容和基于知识并不总是可用的。因此,一些新方法,比如混合系统,已经被设计出用来解决这个问题了。
混合推荐系统
注意,文章到目前为止所介绍的不同类型的推荐系统都互有优劣,他们根据不同的数据给出推荐。 一些推荐系统,如基于知识的推荐系统,在数据量有限的冷启动环境下最为有效。其他系统,如协同过滤,在有大量数据可用时则更加有效。在多数情况下,数据都是多样化的,我们可以为同一任务灵活采用多种方法。 因此,我们可以结合多种不同技术的推荐来提高整个系统的推荐质量。许多的组合性技术已经被探索出来了,包括:
- 加权:为推荐系统中的每种算法都赋予不同的权重,使得推荐偏向某种算法
- 交叉:将所有的推荐结果合在一起展现,没有偏重
- 增强:一个系统的推荐将作为下一个系统的输入,循环直至最后一个系统为止
- 切换:随机选择一种推荐方法
混合推荐系统中的一个最有名的例子是于2006至2009年举行的Netflix Price算法竞赛。这个竞赛的目标是将Netflix的电影推荐系统Cinematch的算法准确率提高至少10%。Bellkor’s Pragmatix Chaos团队用一种融合了107种不同算法的方案将Cinematch系统的推荐准确率提高了10.06%,并最终获得了100万美元奖金。你可能会对这个例子中的准确率感到好奇,准确率其实就是对电影的预测评分与实际评分接近程度的度量。
推荐系统与AI?
推荐系统常用于人工智能领域。推荐系统的能力 - 洞察力,预测事件的能力和突出关联的能力常被用于人工智能中。另一方面,机器学习技术常被用于实现推荐系统。例如,在Arcbees,我们使用了神经网络和来自IMdB的数据成功建立了一个电影评分预测系统。神经网络可以快速地执行复杂的任务并轻松地处理大量数据。通过使用电影列表作为神经网络的输入,并将神经网络的输出与用户评分进行比较,神经网络可以自我学习规则以预测特定用户的未来评分。
专家建议
在这篇文章中,我注意到有两个很重要的建议经常被推荐系统领域内的专家提及。第一,基于用户付费的物品进行推荐。当一个用户有购买意愿时,你就可以断定他的评价一定是更具有相关性与准确的。第二,使用多种算法总是比改进一种算法要好。Netflix Prize竞赛就是一个很好的例子。
实现一个基于物品的推荐系统
下面的代码演示了实现一个基于物品的推荐系统是多么的简单与快速。所使用的语言是Python,并使用了Pandas与Numpy这两个在推荐系统领域中最流行的库。所使用的数据是电影评分,数据集来自MovieLens。
第一步:寻找相似的电影
1.读取数据1
2
3
4
5
6
7
8
9
10import pandas as pd
import numpy as np
ratings_cols = ['user_id', 'movie_id', 'rating']
ratings = pd.read_csv('u.data', sep='\t', names=ratings_cols, usecols=range(3))
movies_cols = ['movie_id', 'title']
movies = pd.read_csv('u.item', sep='|', names=movies_cols, usecols=range(2))
ratings = pd.merge(ratings, movies)
2.构造用户的电影矩阵1
movieRatings = ratings.pivot_table(index=['user_id'],columns=['title'],values='rating')
3.选择一部电影并生成这部电影与其他所有电影的相似度1
2
3
4
5starWarsRatings = movieRatings['Star Wars (1977)']
similarMovies = movieRatings.corrwith(starWarsRatings)
similarMovies = similarMovies.dropna()
df = pd.DataFrame(similarMovies)
4.去除不流行的电影以避免生成不合适的推荐1
2
3
4ratingsCount = 100
movieStats = ratings.groupby('title').agg({'rating': [np.size, np.mean]})
popularMovies = movieStats['rating']['size'] >= ratingsCount
movieStats[popularMovies].sort_values([('rating', 'mean')], ascending=False)[:15]
5.提取与目标电影相类似的流行电影1
2df = movieStats[popularMovies].join(pd.DataFrame(similarMovies, columns=['similarity']))
df.sort_values(['similarity'], ascending=False)[:15]
第二步:基于用户的所有评分做出推荐
1.生成每两部电影之间的相似度,并只保留流行电影的相似度1
2userRatings = ratings.pivot_table(index=['user_id'],columns=['title'],values='rating')
corrMatrix = userRatings.corr(method='pearson', min_periods=100)
2.对于每部用户看过并评分过的电影,生成推荐(这里我们选择用户0)1
2
3
4
5
6
7
8
9
10
11
12
13myRatings = userRatings.loc[0].dropna()
simCandidates = pd.Series()
for i in range(0, len(myRatings.index)):
# Retrieve similar movies to this one that I rated
# 取出与评分过电影相似的电影
sims = corrMatrix[myRatings.index[i]].dropna()
# Now scale its similarity by how well I rated this movie
# 以用户对这部电影的评分高低来衡量它的相似性
sims = sims.map(lambda x: x * myRatings[i])
# Add the score to the list of similarity candidates
# 将结果放入相似性候选列表中
simCandidates = simCandidates.append(sims)
simCandidates.sort_values(inplace = True, ascending = False)
3.将所有相同电影的相似度加和1
2simCandidates = simCandidates.groupby(simCandidates.index).sum()
simCandidates.sort_values(inplace = True, ascending = False)
4.只保留用户没有看过的电影1
filteredSims = simCandidates.drop(myRatings.index)
如何更进一步?
在上面的实例中,Pandas与我们的CPU足以处理MovieLens的数据集。然而,当数据集变得更庞大时,处理的时间也会变得更加漫长。因此,你应该转为使用具有更强大处理能力的解决方案,如Spark或MapReduce。
我希望我已经成功让你看到,实现一个简单而有效的推荐系统中并没有什么复杂之处。如果你有任何问题,不要犹豫,直接评论就好了。