总结
Eureka:服务注册与发现
Ribbon:客户端负载均衡
Hystrix:服务降级、熔断
Feign:集成Ribbon的Spring RestTemplate替代方案
Zuul:服务网关
Config:集中式配置服务
Stream:消息驱动
Sleuth:服务跟踪
Zipkin:服务监控
服务治理 Spring Cloud Eureka
服务注册
服务注册:在服务治理框架中,通常会构建一个服务注册中心,每个服务单元向注册中心登记自己提供的服务并告知主机、端口号、版本号、通信协议等附加信息。
服务发现:服务调用方调用服务时,需要先向服务注册中心咨询服务,并获取所有服务的实例清单。实际的框架为了性能等因素,不会采用每次都向服务注册中心获取服务的方式。
Eureka 服务端就是服务注册中心,用于提供服务的注册与发现;Eureka 客户端则是服务提供者与服务消费者。
服务调用方每次调用服务时都向服务注册中心请求获取所有实例明显是一个不可取的策略,可以考虑引入缓存实现客户端的负载均衡。这样,服务调用方将定期与服务注册中心进行联系并刷新服务实例的缓存,当拿到不健康的实例时,再去向服务中注册重新获取实例。
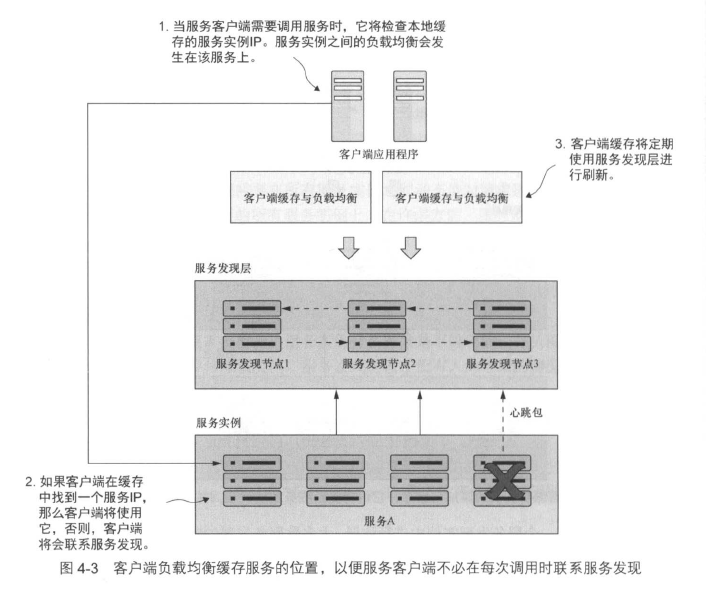
注意,每次服务注册都需要30s才能在Eureka中显示,因为Eureka需要从服务接受3次连续心跳包ping,每次心跳包ping间隔10s。
每个通过Eureka注册的服务都有以下两个ID:
应用程序ID:由
spring.application.name决定,表示一组服务实例实例ID:一个随机数,表示单个服务实例
注册服务后,可通过Eureka的REST API查看所有服务的注册表,默认返回XML,返回JSON需要在Headers中设置Accept字段为application/json:
http://localhost:8761/eureka/apps/<APP_ID>
1 | { |
至此,服务注册基本完成。
服务发现 Spring DiscoveryClient
查找服务实例
使用@EnableDiscoveryClient注解来激活Spring Discovery Client,使应用能够使用Discovery Client和Ribbon库。
注入DiscoveryClient,调用getInstances()方法查找所有服务实例1
2
3
4
private DiscoveryClient discoveryClient;
List<ServiceInstance> instances = discoveryClient.getInstances("yourServiceId");
使用带有 Ribbon 功能的 Spring RestTemplate 调用服务
使用@LoadBalanced注解对RestTemplate添加一个LoadBalancerClient,以实现客户端负载均衡1
2
3
4
5
public RestTemplate getRestTemplate(){
return new RestTemplate();
}
使用 Netflix Feign 客户端调用服务
Netflix Feign客户端是Spring启用Ribbon的Spring RestTemplate类的替代方案。在启动类中添加@EnableFeignClients注解。
在类中使用@FeignClient("yourServiceId")注解标识服务
使用 Spring Cloud 和 Netflix Hystrix 的客户端弹性模式
客户端弹性模式的重点是:在远程服务发生错误或表现不佳时保护远程资源(如另一个微服务调用或数据库查询)的客户端免于崩溃。
这些模式的目标是让客户端“快速失败”,而不消耗诸如数据库连接和线程池之类的宝贵资源,并且可以防止远程服务的问题向客户端的消费者进行“上游”传播。
有4种客户端弹性模式,分别是:
- 客户端负载均衡(client load balance)模式
- 断路器(circuit breaker)模式
- 后备(fallback)模式
- 舱壁(bulkhead)模式
这些模式是在调用远程资源的客户端中实现的,实现的逻辑位于消费远程服务的客户端和资源之间。
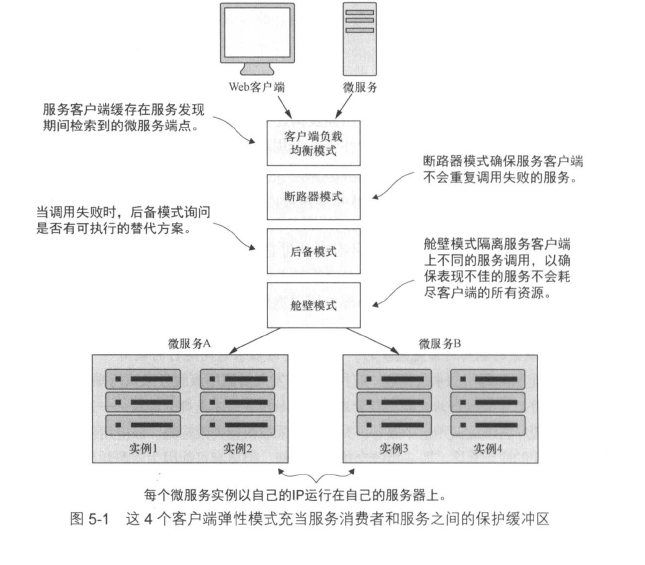
负载均衡模式
即维护一个服务缓存,客户端查找服务实例时不直接从服务注册中心(如Eureka)中拿,而是从缓存中拿。
由于客户端服务均衡器位于服务端和客户端之间,所以它可以检测到服务实例是否抛出错误或表现不佳,从而将该实例从缓存中提前移除,防止将来客户端调用该实例。
Netflix Ribbon 提供了开箱即用的负载均衡功能。
断路器模式
断路器模式是模仿电路断路器的客户端弹性模式。当远程服务被调用时,断路器将监视这个应用,如果调用时间太长,断路器将会介入并中断调用。
此外,断路器将监视所有的远程资源调用,如果对一个资源的调用失败次数足够多,那么断路器就会采用快速失败机制,阻止将来调用失败的远程资源。
断路器提供了:
- 快速失败:当远程服务处于降级状态时,应用程序将会快速失败,并防止拖垮整个应用。在大多数中断情况下,最好是部分服务关闭而不是完全关闭
- 优雅地失败:通过超时和快速失败,开发人员可以寻找替代机制来执行用户意图,例如用户尝试从一个数据源检索数据,并且该数据源正在经历服务降级,那么可以开发人员可以尝试从其他数据源检索该数据
- 无缝恢复:断路器作为中介,可以定期检查所请求资源是否重新上线,并在没有人为干预的情况下重新允许对该资源的访问。
后备模式
在后备模式下,当远程服务调用失败时,服务消费者将执行替代代码路径,并尝试通过其他方式执行操作,而不是生成一个异常。
这通常涉及从另一数据源查找数据,或将用户的请求进行排队以供将来处理。
例如,对于购物网站的用户个性化推荐列表,该服务需要调用微服务对用户的历史行为进行分析再返回推荐结果,但是如果这个个性化推荐服务失败,后备策略是从另一个数据源中获取一个通用的推荐列表。
舱壁模式
舱壁模式是建立在造船的概念基础上的。采用舱壁设计,即使船体被击穿,水也会被隔离在舱壁外。
基于这个概念,可以使用线程池充当服务的“舱壁”,把远程资源的调用分到线程池中,这样就可以降低一个缓慢的远程资源调用拖垮整个应用的风险。
每个远程资源都是隔离的,并分配给线程池。
使用
使用
@EnableCircuitBreaker注解,加入至引导类中。在方法前加入
@HystrixCommand注解,在任何时候调用该方法,Hystrix都将包装这个调用。当调用时间超过 1000ms 时,Hystrix将中断调用并抛出一个com.nextflix.hystrix.exception.HystrixRuntimeException异常。
定时断路器
通过设置commandProperties属性,可以实现自定义Hystrix的服务调用超时时间,当然也还可以定制其他的附加属性。1
2
3// 调用超时时间设为12s
(commandProperties={
(name="execution.isolation.thread.timeInMilliseconds", value="12000")})
实现后备策略
在fallbackMethod属性中可以定义一个后备方法,如果来自Hystrix的调用失败,就会调用该方法。该方法需要和@HystrixCommand注解的方法在同一类中。
1 | (fallbackMethod = "yourFallBackMethod") |
使用后备机制需要注意:
- 后备是一种在资源超时或失败时提供行动方案的机制。如果需要使用后备来捕获超时异常,就需要在服务调用周围使用
try catch,并在catch中记录日志 - 注意后备方法,如果后备方法也是另一个微服务,则可能也需要用
@HystrixCommand来保护该服务。在主要的行动方案中的失败,可能也会影响到备用的行动方案,需要注意。
使用线程池实现“舱壁”隔离服务调用
Hystrix使用线程池来处理所有对远程服务的请求,在使用没有任何配置的默认@HystrixCommand注解时,会将所有远程服务调用都放在同一线程池下,默认情况下这个线程池中有10个线程,这可能会导致应用出现问题。在存在高并发的情况下,一个服务可能会导致Java容器中的所有线程都被阻塞,最终崩溃。
例如,如果某些服务突然涌入大量请求,会导致这个服务占用了所有该线程池中的所有线程,其他服务将无法处理它们收到的请求。
舱壁模式将远程资源调用隔离在它们自己的线程池中,从而控制了单个出现问题的服务。
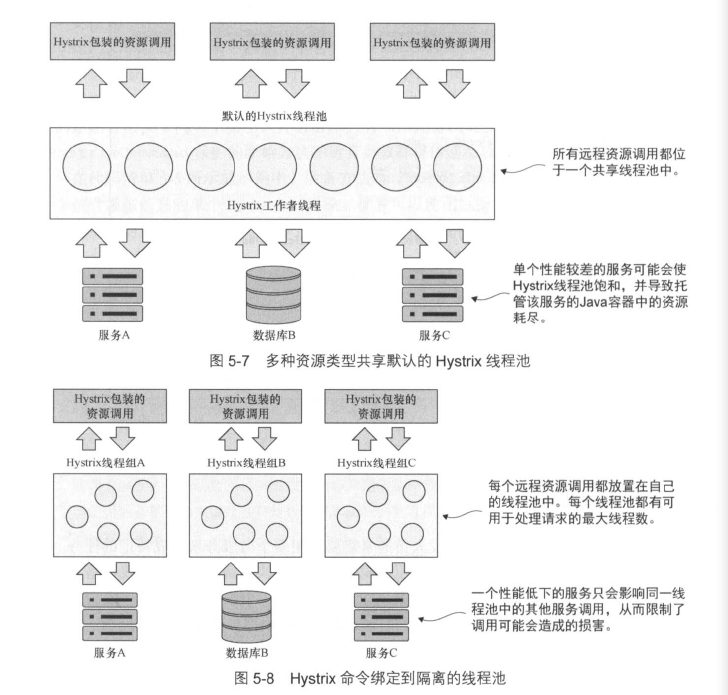
实现隔离的线程池,需要用到@HystrixCommand注解的其他属性:1
2
3
4
5
6
7(
// 线程池的唯一ID
threadPoolKey = "yourThreadPool",
threadPoolProperties =
// 线程池最大容量 和 线程池满时的阻塞队列大小
{(name = "coreSize",value="30"),
(name="maxQueueSize", value="10")})
将maxQueueSize属性设为-1,会使用SynchronousQueue,大于1则会使用LinkedBlockingQueue。
关于线程池的大小如何设置,Netflix推荐以下公式:1
服务健康状态时的每秒支持最大请求数 x 第99百分位延迟时间(s) + 用户缓冲的少量额外线程
例如,第99百分位延迟时间为1s,意味着99%的请求处理时间不到1s。
微调 Hystrix
Hystrix不仅能实现超时时间调用的熔断,还能监控调用失败的次数,如果调用次数足够多,那么Hystrix同样会熔断。
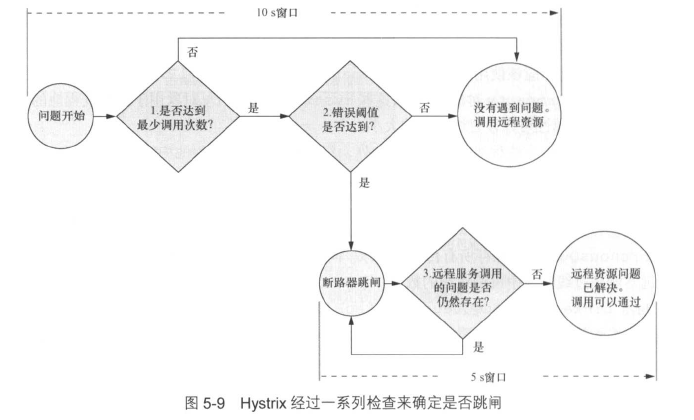
下图是Hystrix远程资源调用失败时的决策过程。
当Hystrix遇到服务错误时,会执行以下步骤:
- 开始一个10s(可配置)的计时器,查看10s内发生的服务调用数量,如果次数少于最小调用次数(默认为20),那么即使有几个调用失败,Hystrix也不会采取行动。例如,10s内有18次服务调用,其中有15次服务调用失败,但由于没达到最小调用次数,Hystrix会继续让调用通过,到达远程服务。
- 如果超过最小调用次数,那么Hystrix将会开始查看调用失败的百分比。如果超过默认的调用失败百分比阈值(50%),就会触发熔断,使将来所有的调用都失败。
- 当触发熔断时,Hystrix会尝试启动一个新的活动窗口,每隔5s(可配置)允许一个调用到达这个已经“出现了问题”的服务。如果调用成功,那么Hystrix将重置熔断并重新允许调用通过。如果调用失败,则保持熔断,并在另一个5s内尝试上述步骤。
在@HystrixCommand注解中可以实现配置以上的参数:1
2
3
4
5
6
7
8
9
10
11
12
13(
commandProperties={
// 10s内的最小调用次数
(name="circuitBreaker.requestVolumeThreshold", value="10"),
// 调用失败份百分比阈值(%)
(name="circuitBreaker.errorThresholdPercentage", value="75"),
// 熔断后允许一个调用通过的时间(ms)
(name="circuitBreaker.sleepWindowInMilliseconds", value="7000"),
// 监视服务调用问题的计时器(即上述的10s)
(name="metrics.rollingStats.timeInMilliseconds", value="15000"),
// 搜集在计时器范围内的服务调用失败次数的桶数量
(name="metrics.rollingStats.numBuckets", value="5")}
)
Hystrix将在桶中收集服务调用失败的次数,注意,metrics.rollingStats.timeInMilliseconds必须能被metrics.rollingStats.numBuckets所整除。在上面的配置中,将使用15秒的定时器,并用5个长度为3秒的桶收集失败次数。桶的数量越多,定时器时间越短,收集失败次数的粒度就越小,但也会加剧CPU占用。
通过@DefaultProperties注解,可以设定默认的Hystrix配置。
Hystrix 与线程上下文
当一个@HystrixCommand被执行时,可以使用两种不同的隔离策略——THREAD和SEMAPHORE(信号量)来运行。默认情况下是以THREAD隔离策略允许,该线程池不与父线程共享上下文,这意味着中断线程的执行,不会中断执行原始调用的父线程。
基于SEMAPHORE的隔离,不需要启动一个新线程,而且如果调用超时,就会中断父线程。
通过excution.isolation.strategy属性可以配置隔离策略:
1 | ( |
在默认情况下,Hystrix开发团队建议使用默认的THREAD策略,可以保持与父线程更高层级的隔离。SEMAPHORE隔离模型比THREAD隔离模型更轻量级,SEMAPHORE适用于并发量很大且使用异步I/O的模型(如Netty)。
Hystrix 与 ThreadLocal
在默认情况下,Hystrix不会将父线程的上下文传递给由Hystrix管理的线程中,这意味着在副线程中设置的ThreadLocal值都是取不到的。
但所幸Spring与Hystrix提供了一种HystrixConcurrencyStrategy机制,可以将父线程的上下文传递给Hystrix线程池中的线程。
实现自定义的HystrixConcurrencyStrategy需要以下3个操作:
- 定义自定义的Hystrix并发策略类
- 定义一个Callable类,将UserContext注入Hystrix命令中
- 配置Spring Cloud以使用自定义Hystrix并发策略
1 | // 第1步,定义自定义的Hystrix并发策略类 |
下一步,实现执行传递的Callable类。
1 | // 第2步,定义一个Callable类,将UserContext注入Hystrix命令中 |
最后配置Spring Cloud1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
// 3.配置Spring Cloud以使用自定义Hystrix并发策略
public class ThreadLocalConfiguration {
(required = false)
private HystrixConcurrencyStrategy existingConcurrencyStrategy;
public void init() {
// 保留现有的Hystrix插件的引用
// 先获取其他所有的Hystrix,再依次重新设置Hystrix插件
// 注意,Hystrix只允许一个HystrixConcurrencyStrategy
HystrixEventNotifier eventNotifier = HystrixPlugins.getInstance()
.getEventNotifier();
HystrixMetricsPublisher metricsPublisher = HystrixPlugins.getInstance()
.getMetricsPublisher();
HystrixPropertiesStrategy propertiesStrategy = HystrixPlugins.getInstance()
.getPropertiesStrategy();
HystrixCommandExecutionHook commandExecutionHook = HystrixPlugins.getInstance()
.getCommandExecutionHook();
HystrixPlugins.reset();
// 使用Hystrix插件注册自定义的HystrixConcurrencyStrategy
HystrixPlugins.getInstance().registerConcurrencyStrategy(new ThreadLocalAwareStrategy(existingConcurrencyStrategy));
// 重新注册其他组件
HystrixPlugins.getInstance().registerEventNotifier(eventNotifier);
HystrixPlugins.getInstance().registerMetricsPublisher(metricsPublisher);
HystrixPlugins.getInstance().registerPropertiesStrategy(propertiesStrategy);
HystrixPlugins.getInstance().registerCommandExecutionHook(commandExecutionHook);
}
}
使用 Spring Cloud 和 Zuul 进行服务路由
接下来将使用Spring Cloud和Zuul完成以下操作:
- 将所有服务调用放在一个URL后面,并使用服务发现将这些调用映射到实际的服务实例
- 将关联ID注入进流经服务网关的每个服务调用中
- 再从客户端发挥的HTTP响应中注入关联ID
- 构建一个动态路由机制,将各个具体的组织路由到服务实例端点,该端点与其他人使用的服务实例端点不同
服务网关
服务网关位于客户端与各个服务的所有调用之间,从服务客户端调用中分离出路径,并确定服务客户端正在尝试调用哪个服务。有了服务网关,服务客户端永远不会直接调用单个服务的URL,而是将所有调用都放到服务网关上。
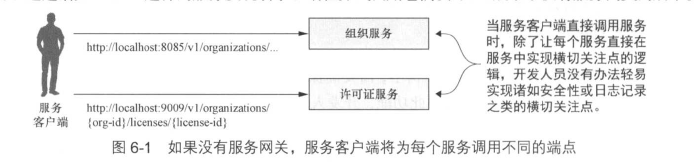
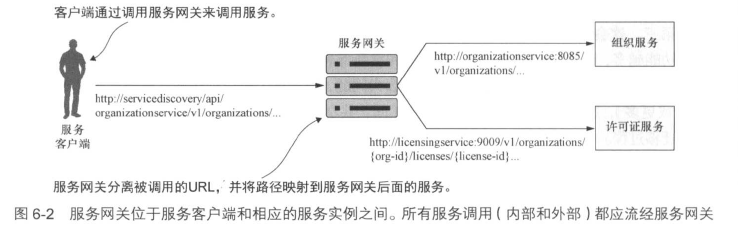
通过服务网关可以实现:
- 静态路由
- 动态路由
- 验证和授权
- 度量数据收集和日志记录
注意,服务网关也可能成为单点故障和潜在瓶颈。因此,需要注意以下几点:
- 将上文提到的的负载均衡器应该放在多个服务网关实例前,而不是所有服务实例前,这确保服务网关实现可以伸缩。
- 保持为服务网关编写的代码是无状态的,不要在服务网关中存储任何信息,因为这样会限制网关的可伸缩性,导致不得不确保在所有网关实例中复制数据。
- 保持为服务网关编写的代码是轻量的,服务网关是服务调用的“阻塞点”,具有多个数据库调用的复杂代码可能会导致难以追踪的性能问题。
使用 Spring Cloud 和 Zuul 实现服务网关
通过在启动类中加入@EnableZuulProxy注解来开启Zuul服务,Zuul的核心就是一个反向代理。
接着配置Zuul与Eureka进行通信,在application.yml中写入配置。
在 Zuul 中映射微服务路由
Zuul要与下游服务器进行通信,必须知道如何将进来的调用请求映射到下游路由,Zuul有以下几种机制来做到这一点:
- 通过服务发现自动映射路由
- 使用服务发现手动映射路由
- 使用静态URL手动映射路由
通过服务发现自动映射路由
Zuul的所有路由映射都是通过在application.yml中定义路由来完成的。但是Zuul也可以根据其服务ID自动路由请求,而不需要配置。
使用自动路由时,Zuul只基于Eureka服务ID来公开服务,如果服务实例没有在运行,Zuul将不会公开该服务的路由。
使用服务发现手动映射路由
通过在application.yml配置,可以实现手动映射路由:1
2
3
4
5
6zuul:
prefix: /api
routes:
licensingservice: /licensing/**
# 不使用Eureka来公开服务
ignored-services: '*'
使用静态URL手动映射路由
Zuul 可以用来路由那些不受Eureka管理的服务。在这种情况下,可以建立Zuul直接路由到其他服务(甚至不是Java的外部服务)。1
2
3
4
5zuul:
routes:
licenseservice:
path: /licensestatic/**
url: http://licenseservice-static:8081
Zuul 和服务超时
Zuul使用Hystrix和Ribbon来防止服务调用超时影响服务网关的性能,在默认情况下,对于任何超过1s处理时间的请求,Zuul会终止并返回一个HTTP 500错误。这个时间可以通过hystrix.command.default.execution.isolation.thread.timeoutInMilliseconds属性来为所有通过Zuul运行的服务设置Hystrix超时。
如果要为特定服务设置超时,则需要将上述的.default改为.yourservicename。
构建过滤器以使用关联 ID 并进行跟踪
Zuul支持以下3种Lexington的过滤器:
前置过滤器:前置过滤器正在Zuul将实际请求发送到目的地前被调用。前置过滤器通常可以在HTTP请求到达实际服务之前对HTTP进行检查和修改,实现验证和授权。前置过滤器不能将用户重定向到不同的端点或服务。
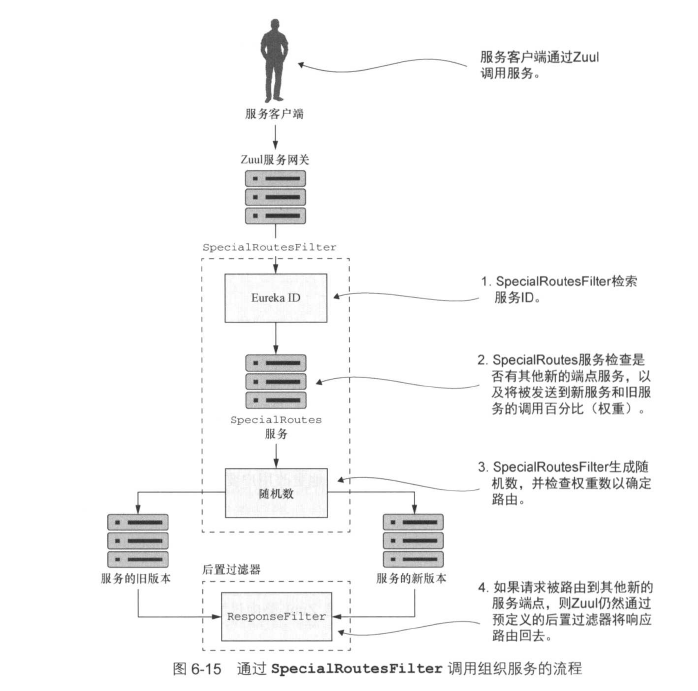
路由过滤器:路由过滤器在调用目前服务之前拦截调用。路由过滤器通常用来确定是否需要进行某些级别的动态路由。例如,将同一服务的两个不同版本之间进行路由,以便将一小部分的服务调用路由到新版本,这样就能在大部分人使用原有服务的情况下,让少部分人体验新功能。(AB测试?灰度发布?)
后置过滤器:后置过滤器在目标服务被调用后,响应发送会客户端后被调用。后置过滤器通常用来记录从目标服务返回的响应、处理错误或审核对敏感信息的响应。
各个过滤器的流程如下:
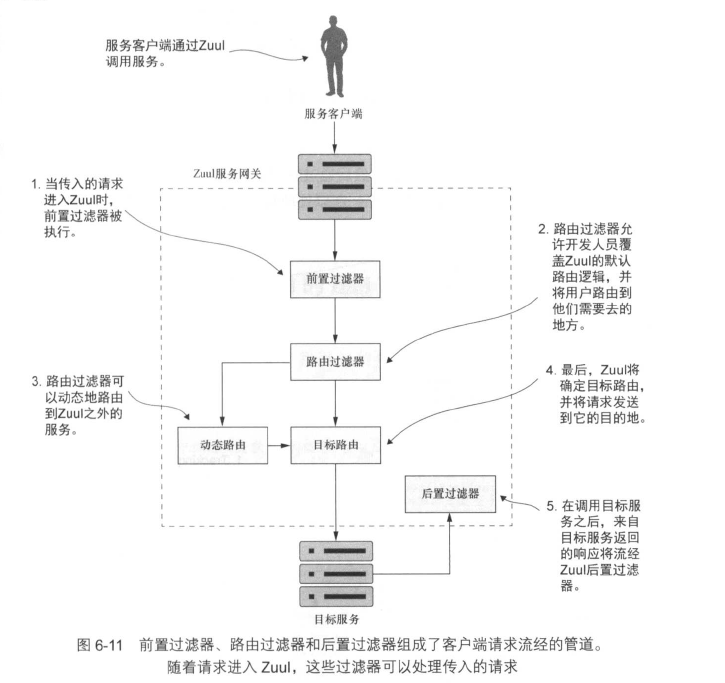
注意,路由过滤器并不会执行HTTP重定向,而是终止传入的HTTP请求,然后代表原始调用者调用路由。这意味着路由过滤器必须完全负责动态路由的调用,并且不能执行HTTP重定向。
实现Zuul Filter必须继承ZuulFiter类,并重写以下4个方法:
fliterType( ):用来告诉Zuul过滤器的种类fliterOrder( ):返回一个整数值,指示不同类型的过滤器的执行顺序shouldFliter( ):返回一个Bool值来指示该过滤器是否要执行run( ):每次服务通过过滤器时执行的业务逻辑
通过以下方法,可以向HTTP Request首部添加唯一的关联ID:1
RequestContext.getCurrentContext().addZuulRequestHeader(USER_ID, userId);
接着,可以使用一个Fliter从HTTP Request首部中拿到关联ID,并存在ThreadLocal中,然后使用一个Interceptor确保所有出站调用都具有关联ID。
使用后置过滤器,可以将关联ID存入HTTP Response首部中,再返回给服务调用者。
构建动态路由过滤器
保护微服务
OAuth2
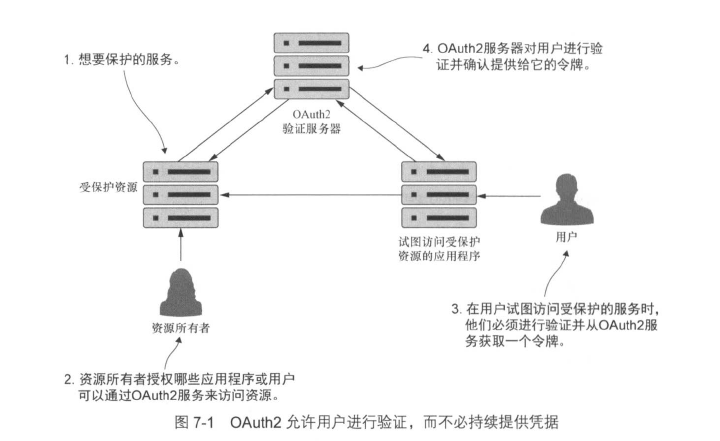
OAuth2是一个基于令牌的安全验证和授权况下,它将安全性分解为以下4个组成部分:
- 受保护资源:这是开发人员想要保护的资源(在书中就是一个微服务),需要确保只有已通过验证并且具有适当授权的用户才能访问它。
- 资源所有者:资源所有者定义哪些应用程序可以调用其服务,哪些用户可以访问该服务以及他们可以使用该服务完成哪些事情。资源所有者注册的每个应用程序都将获得一个应用程序名称,该应用程序名称和应用程序密钥一起标识应用程序,这两者的组合也是验证OAuth2令牌时传递的凭据的一部分。
- 应用程序:代表用户调用服务的应用程序,用户很少会直接调用服务,而是依赖应用程序为他们工作。
- OAuth2验证服务器:OAuth2验证服务器是应用程序和正在使用的服务之间的中间人。
以上4个组成部分相互作用对用户进行验证,用户只需提交他们的凭据。如果成功通过校验,则会出示一个验证令牌,该令牌可以在服务之间传递。
OAuth2规范具有以下4种类型的授权:
- 密码
- 客户端凭证 client credential
- 授权码 authorization code
- 隐式 implicit
验证和授权的区别:
验证(authentication):验证是用户通过提供凭据来证明他们是谁的行为
授权(authorization):授权决定是否允许用户做他们想做的事情
使用 Spring Cloud Stream 的事件驱动架构
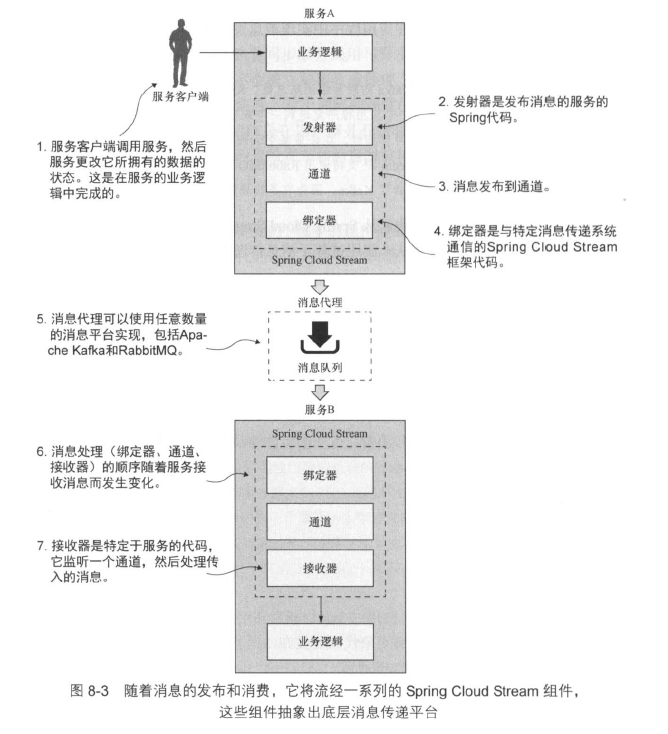
Spring Cloud中有4个组件涉及发布消息和消费消息:
- 发射器(source):服务使用发射器来发布消息,发射器是一个Spring注解接口,它接收一个普通Java对象(POJO),该对象代表要发布的消息。发射器接收消息并序列化(默认为Json)后发布到通道。
- 通道(channel):通道是对队列的一个抽象。
- 绑定器(binder):绑定器是Spring Cloud Stream的一部分,负责与特定消息平台通讯。
- 接收器(sink):服务通过接收器从MQ中接收消息。接收器监听从通道传入的消息并反序列为POJO。
使用 Spring Cloud Sleuth 和 Zipkin 进行分布式跟踪
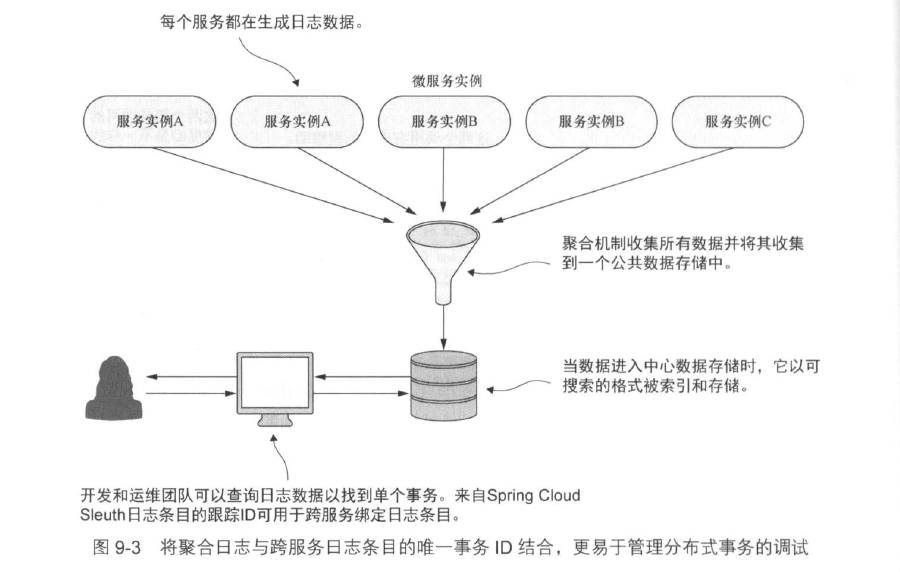
Spring Cloud Sleuth将关联ID装配到HTTP调用上,通过过滤器与其他Spring组件进行交互,将生成的关联ID传递到所有系统调用。
通过@EnableZipkinServer注解开启Zipkin服务,然后在服务应用的application.yml中加入以下配置:1
2
3
4
5
6
7
8spring:
zipkin:
# zipkin服务器地址
base-url: http://localhost:8080
sleuth:
sampler:
# 日志输出百分比
percentage: 1
为所有服务发送跟踪消息,可以设置spring.sleuth.sampler.percentage = 1,也可以使用AlwaysSampler替换Spring Cloud Sleuth 中默认的 Sampler类:
1 |
|
监控与管理
Actuator
通过 pom.xml 导入
1 | <dependency> |
即可通过 /health,/beans,/env,/metrics 等端点获得对应监控信息。
例如 /metrics:1
2
3
4
5
6
7
8
9
10
11
12
13
14{
"mem": 248408,
...
"gc.ps_scavenge.count": 7,
"gc.ps_scavenge.time": 95,
"gc.ps_marksweep.count": 1,
"gc.ps_marksweep.time": 55,
"httpsessions.max": -1,
"httpsessions.active": 0,
"gauge.response.hello": 11,
"gauge.response.metrics": 60,
"counter.status.200.metrics": 1,
"counter.status.200.hello": 1,
}
其中:
gauge.*:HTTP 请求性能指标之一,表示一个绝对数值,例如 gauge.response.hello:11表示上一次 hello 请求的延迟为 5 毫秒counter.*:HTTP 请求性能指标之一,作为计数器使用,例如 counter.status.200.hello:1 表示 hello 请求返回 200 状态码的次数为 1
通过注入org.springframework.boot.actuate.metrics.CounterService 与 org.springframework.boot.actuate.metrics.GaugeService 可以实现访问指定端点的统计信息
例如增加 counterService.increment("hello.count");,返回结果:1
"counter.hello.count": 1
此外,可以通过实现 org.springframework.boot.actuate.health.HealthIndicator 接口来实现对其他没有被 Spring 封装的组件的监测。
如果需要远程关闭应用,可以在配置文件中加入以下字段,这样向服务器 POST /shutdown 就可以实现远程关闭应用:1
endpoints.shutdown.enabled=true