概述
1 | public class HashMap<K,V> extends AbstractMap<K,V> |
HashMap 是一个使用数组与链表(红黑树)实现的键值对集合,继承自抽象类 AbstractMap,实现了 Map 、Cloneable、Serializable 接口。
HashMap 是非线程安全的,key 与 value 允许 null 值(key的 null 只允许有一个,value无限制),遍历顺序和插入顺序不保证不一致。
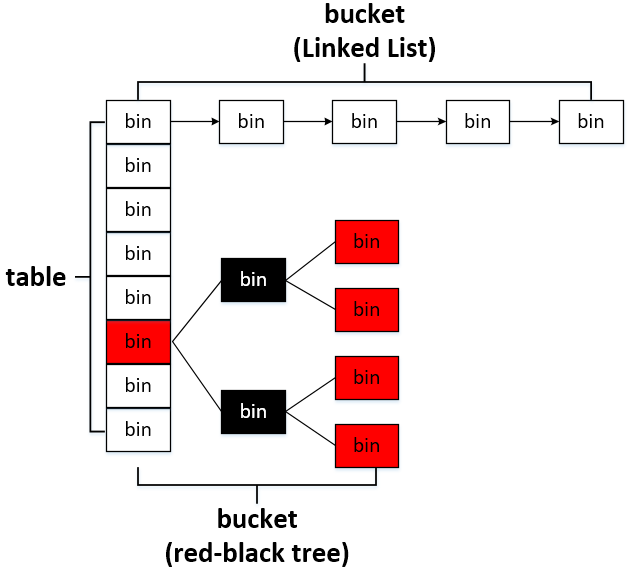
几个重要参数
- DEFAULT_INITIAL_CAPACITY:默认容量,为 2 的 4 次方(16)
- loadFacotr:负载因子,默认为 0.75,如果实际 entry 数量超过了 capacity与loadFacotr 的乘积,将会进行resize
- MAXIMUM_CAPACITY:最大容量,默认为 2 的 30 次方
- TREEIFY_THRESHOLD:树化阈值,默认为 8,当 Bins内 的 Node 超过该数值,会将链表转成红黑树
- UNTREEIFY_THRESHOLD:链表化阈值,默认为 6,当 Bins 内的 Node 小于该数值,会将红黑树转成链表转成
- MIN_TREEIFY_CAPACITY:链表转树的最小容量,,默认为 64,只有容量超过该值才能进行树化。这个值至少是 4 * TREEIFY_THRESHOLD, treeifyBin() 方法中会先判断容量,如果小于 64 会直接 reszie 而不是 树化。
HashMap 是如何计算 hashCode 的
真正的 hash 值是将 key.hashCode 右移 16 位,然后与原来的 key.hashCode 做异或计算得到的,即对原来的 hashCode 做一个扰动的处理。
实际上就是将原始 hashCode 的高 16 位和低 16 位进行异或,这样就混合了原始 hashCode 的高位和低位,加大了低位的随机性,而且混合后的低位掺杂了高位的部分特征,这样高位的信息也被变相保留下来,这就使得 hash 方法返回的值,具有更高的随机性,减少了冲突的可能性。
1 |
|
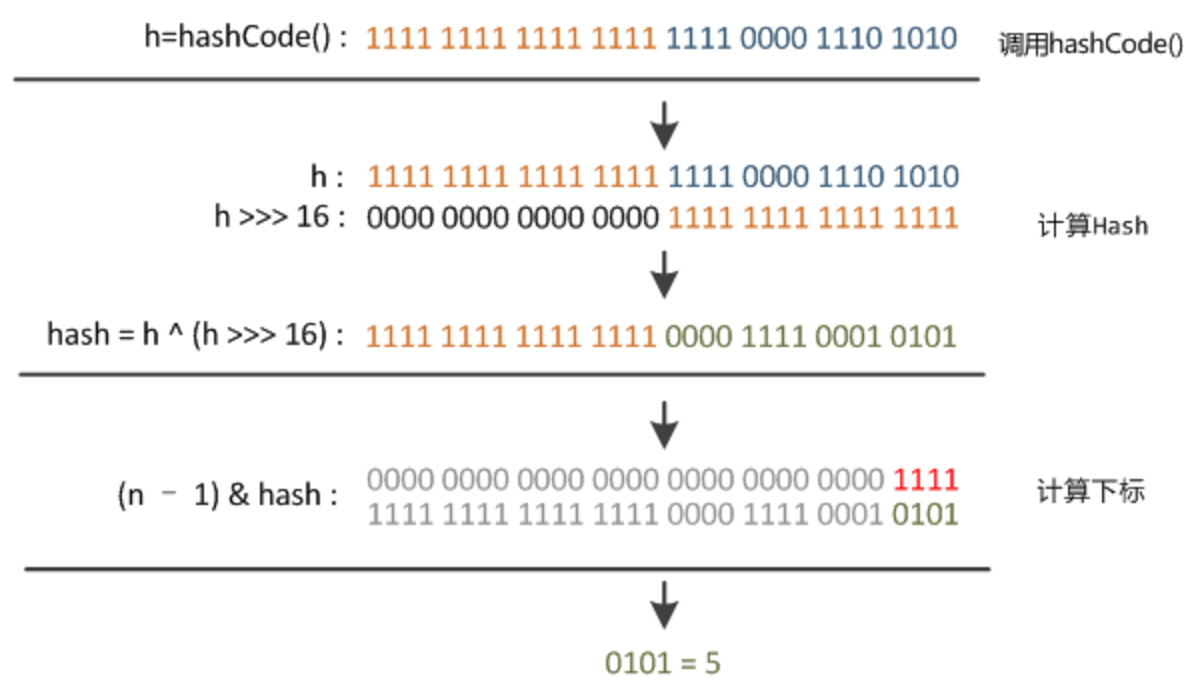
此外,Node 内部类中的 hashCode 是由 key 的 hashCode 和 value 的 hashCode 异或得到的。
1 | public final int hashCode() { |
负载因子的大小
一般来说,默认的load factor (0.75) 在时间和空间成本上提供了很好的权衡。
load factor 越小,HashMap 所能容纳的键值对数量变少,哈希碰撞也会减少,但空间利用率低。
load factor 越大(可以大于1),HashMap 所能容纳的键值对数量变多,空间利用率高,但碰撞率也高,也提高了查找成本。
为什么 HashMap 容量为 2 的幂
当容量为 2 的 n 次幂的时候,在 put 的时候不同的 key 算出的 index 相同的几率较小,分布较均匀,不容易发生碰撞。
从 put 策略中的计算 index 方式可以看出实际是对 length-1 与 hash(key) 做与运算,2^n 转换成二进制就是1+n个0,减1之后就是0+n个1,如16 -> 10000,15 -> 01111。
根据与运算的规则,都为1(真)时,才为1,因为2^n-1都是11111结尾的,所以碰撞几率小。
且当容量一定是2^n时,h & (length - 1) == h % length,位运算可以提高效率。
HashMap 的 Put 策略
注意,HashMap 在真正第一次 put 的时候才会进行初始化。
- 判断当前数组是否需要初始化
- 根据 key 的 HashCode 计算放置桶的 index
判断是否空桶 or 是否发生 Hash 碰撞
解决 Has h碰撞:根据桶是红黑树还是链表进行对应的插入操作
- 如果是链表形式,完成插入后,检查是否超过树化阈值,超过将链表转为红黑树
- 如果节点已经存在就替换 old value
- 最后检查实际元素个数是否超过 capacity 与 loadFacotr 的乘积,超过进行 resize
HashMap 中计算 index 的方式为index = (容量 - 1) & hash(key),即:
1 | p = tab[i = (n - 1) & hash]) |
- 计算 key 的 HashCode
- 和数组的容量减 1 做一次 “与” 运算(&)
HashMap 的 Get 策略
1 | if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) |
- 根据 key 的 HashCode 找到对应桶的 index (
index = (容量 - 1) & hash(key)) - 判断是否为链表,不是链表,判断 hashCode 是否相等且用 == 判断 key 是否相等,或者直接判断 key.equals(k)
- 判断是否为红黑树,是红黑树调用 getTreeNode() 方法
- 不是红黑树,遍历链表寻找节点,判断 hashCode 是否相等且用 == 判断 key 是否相等,或者直接判断 key.equals(k)
HashMap 的 Remove 策略
- 根据 key 的 HashCode 找到对应桶的 index,这一步和 get 中找 index 的方式是一样的
- 如果是 TreeNode,调用红黑树的getTreeNode()删除节点
- 否则, 遍历链表,判断 hashCode 是否相等且用 == 判断 key 是否相等,或者直接判断 key.equals(k)
- 找到则删除
1 | if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) |
PS:其实第二句 (k = e.key) == key ||(key != null && key.equals(k) 等价于key.equals(k),多出的 (k = e.key) == key 可以减少后面调用 equals(),提高效率。
HashMap 的扩容 (reszie) 策略
源码注释中已明确指出:resize 后元素下标要么不变,要么增加 2 的幂
- 计算新桶数组的容量 newCap 和新阈值 newThr
- 检查当前容量已超过MAXIMUM_CAPACITY(),超过则将容量设为 Integer.MAX_VALUE(2的31次方-1),不进行扩容
- 根据新的容量初始化一个 newTab
- 如果节点是 TreeNode 类型,则需要拆分红黑树
- 如果是链表,则先遍历 oldTab 中的元素,计算该元素 e 的 e.hash & oldCap 是否等于 0
- 等于0,放入原来的index,否则放入 index + oldCap(原有容量)
可以看出 resiez 是个成本很高的操作,所以在存储大量数据的时候,最好预先指定 HashMap 的 size ,而且保证0.75size > 数据量。
PS:在 JDK1.7 中如果在新表的数组索引位置相同,则链表元素会倒置。
HashMap 如何解决哈希碰撞(冲突)
常见的哈希碰撞解决方法:
- 开放地址法(可以占用本来应该其他数据占用的地址):
- 线性探测再散列:冲突发生时,找到下个为空的位置存放。
- 二次探测再散列:冲突发生时,在表的左右进行跳跃探测。
- 随机探测再散列:产生一个随机数序列,将此随机数序列作为依次探测的步长。
- 链地址法:所有哈希值相同的元素构成一个称为同义词链的单链表,HashMap 采用的是这种方法。
- 再哈希法:同时构造多个不同的哈希函数,如果出现哈希值相同的元素,用其他哈希函数再做一次哈希。
- 建立公共溢出区:将哈希表分为基本表和溢出表两部分,凡是和基本表发生冲突的元素,一律填入溢出表。
HashMap 的具体解决办法:
当 HashMap 出现哈希碰撞时,它会首先检查新键和当前检索到的键之间是否可以比较(也就是实现Comparable接口)。
如果不能比较,它就会通过调用 tieBreakOrder(Object a,Object b) 方法来对它们进行比较。
这个方法首先会比较两个键对象的类名,如果相等再调用 System.identityHashCode方法(比较内存地址)进行比较。
HashMap 并发下的死循环与元素丢失
JDK1.7 中的 HashMap 在并发的情况下,resize 时可能会产生环形链表(新的链表采用头插法,为逆序插入),在执行 get 的时候,会触发死循环。
但 JDK1.8 中新数组中的链表顺序依然与旧数组中的链表顺序保持一致,但仍有可能发生元素丢失等问题。
HashMap 自己实现 writeObject 和 readObject 方法的原因
HashMap 多数情况都不是满的,序列化未使用的部分,浪费空间。
HashMap 依靠 HashCode 来存放 Entry,而在不同的 JVM 实现中计算得出的 HashCode 可能是不同的,这样会导致 HashMap 的反序列化结果与序列化之前的结果不一致。
第 2 点在《Effective Java》中有提到:
The bucket that an entry resides in is a function of the hash code of its key, which is not, in general, guaranteed to be the same from JVM implementation to JVM implementation. In fact, it isn’t even guaranteed to be the same from run to run. Therefore, accepting the default serialized form for a hash table would constitute a serious bug. Serializing and deserializing the hash table could yield an object whose invariants were seriously corrupt.
那么,HashMap 又是如何保证序列化和反序列化数据的一致性的?
首先,将底层的 table 数组用
transient修饰,保证不被自动序列化。然后序列化的时候并不会将数组直接序列化,而是将 size 以及每个 k-v 对都进行序列化。
在反序列化的时候,重新计算 k-v 对的位置,重新填充一个数组。
采用自定义对象作为 HashMap 的key 时的注意事项
- 要注意这个对象是否为可变对象,否则可能导致存入Map中的数据无法取出,造成内存泄漏。
- 要重写 hashCode() 方法和 equals() 方法。
红黑树的特点
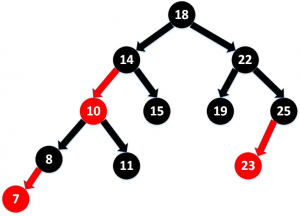
- 每个节点非红即黑
- 根节点总是黑色的
- 如果节点是红色的,则它的子节点必须是黑色的,反之不一定
- 每个叶子节点都是黑色的空节点(NIL节点)
- 从根节点到叶节点或空子节点的每条路径,必须包含相同数目的黑色节点,即相同的黑色高度
源码阅读
1 | package java.util; |