前言
在毕设的 API 模块中,考虑到分布式环境下采用 UUID 直接生成 Key 可能会导致 Key 重复的问题,最终的 Key 生成策略采用 Twitter Snowflake 算法生成唯一 ID, 再使用 HmacMD5 算法对 ID 加密生成 API Key。
其他常见的分布式唯一 ID 生成策略还有:
数据库自增字段
UUID
Mongdb objectID
Redis 原子命令 INCR
ZooKeeper 的 ZNode 数据版本生成序列号,可以生成 32 位和 64 位的数据版本号
美团的 Leaf 系统 (类似 Twitter Snowflake 但通过 ZooKeeper 解决了时钟回拨问题)
Twitter Snowflake 算法
Snowflake 是 Twitter 开源的分布式 ID 生成算法,目的是在分布式系统中生成全局唯一且趋势递增的 ID,属于划分命名空间并行生成的一种算法,其生成结果为 64bit 的 long 型 ID。Snowflake 算法可以保证每秒至少生成约 409.6万个不重复的 ID,具有极高的性能。
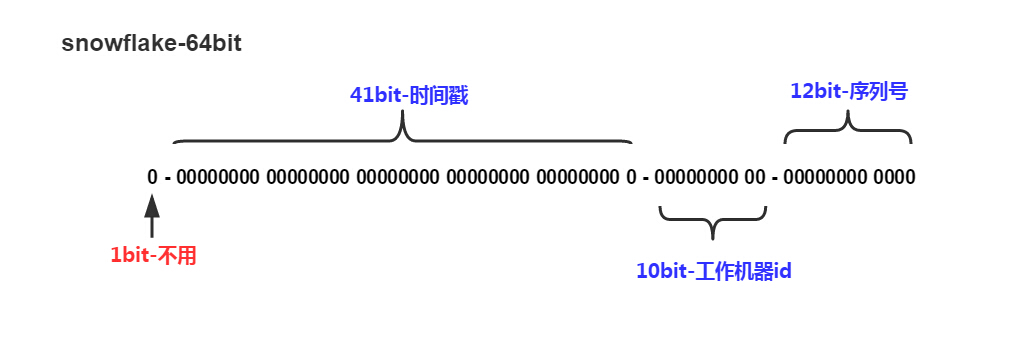
其中:
- 符号位:占 1 位,其值始终是 0,无实际作用。
- 时间表示位:占 41 位,用来记录时间戳(毫秒),可以表示 $0$ 至 $2^{41}-1$ 毫秒约等于 69 年的时间。
- 数据中心位:占 5 位,可表示 $0$ 至 $2^{5}-1$ 共 32 个数据中心。
- 机器编号位:占 5 位,每个数据中心内可表示 $0$ 至 $2^{5}-1$ 共 32 个机器。
- 序列编号位:占 12 位,用来记录同毫秒内产生的不同 ID,可表示 $0$ 至 $2^{12}-1$ 共 4096 个序列号。
注意,在 12 位的生成序列编号位时,都会获取当前的 Timestamp, 然后会分为两种情况处理:
- 如果当前的 Timestamp 比前一个 ID 的 Timestamp 大, 随机生成一个初始 sequence number (12bits) 作为本毫秒内的第一个 sequence number;
- 如果当前的 Timestamp 和前一个已生成 ID 的 Timestamp 相同 (在同一毫秒中),就用前一个 ID 的 sequence number + 1 作为新的 sequence number (12 bits)。 如果本毫秒内的所有 ID 用完,阻塞到下一毫秒继续 (阻塞过程中不会生成新的 ID)。
优点:
- 不依赖于数据库,灵活方便,且性能优于数据库。
- 毫秒数在高位,自增序列在低位,整个 ID 都是趋势递增的。
- 可以根据自身需求分配 bit 位,非常灵活。
缺点:
若由于时间校准或其他原因导致时间回拨,而回拨前恰好生成过一批 ID,时间回拨后可能会出现重复 ID。Twitter 官方没有对此给出解决方案,仅做抛出错误处理。(思考:每秒生成的 409.6 万个 ID 显然是无法全部用完的,如果出现回拨,可利用先前没用过的这些 ID。)
生成 ID 在单机上是递增的,但在分布式环境下每台机器上的时钟不可能完全同步,有时候会出现不是全局递增的情况。
Java 实现
1 | public class SnowflakeIdGenerator { |