关键词
数据类型、范式与反范式、B-Tree索引、Hash索引。
Scheme 与数据类型优化
在 MySQL 中,Scheme 与 Database 是等价的,可视为表的集合。
选择优化的数据类型
选择数据类型的原则:
- 更小的通常更好:使用可以正确使用存储数据的最小数据类型。
- 简单就好:简单数据类型的操作意味着更少的 CPU 开销,例如整形和字符操作代价更低。这里的例子是一使用 MySQL 自建的类型而不是字符串来存储日期和时间,二是用整形存储 IP 地址。
- 尽量避免NULL:可为 NULL 的列使得索引、索引统计和值比较都更复杂,且会使用更多的存储空间。当可为 NULL 的列被索引时,每个索引记录需要一个额外的字节。
例如,DATETIME 和 TIMESTAMP 都可以存储日期和时间,精确到秒,然而 TIMESTAMP 只使用 DATETIME 一半的存储空间,且会根据时区自动变化。另一方面,TIMESTAMP 允许的时间范围要更小,且时区自动更新有时反而会成为障碍。
整数类型
整数类型包括:TINYINT(8位),SMALLINT(16位),MEDIUMINT(24位),INT(32位),BIGINT(64位)。它们可以存储从$-2^{N-1}$ 到 $2^{N-1}-1$ 范围的整数,其中 $N$ 为位数。
整数类型有可选的属性 UNSIGNED,表示不允许负值,可以使正数的表示范围提高一倍,例如 TINYINT.UNSIGNED 可以存储 0~255,而 TINYINT 是 -128~127。
虽然 MySQL 可以为整数类型指定宽度,但实际并不会限制值得合法范围,只是规定了一些 GUI 的显示位数。对于存储和计算来说,INT(1) 和 INT(10) 是相同的。
实数类型
实数是带有小数部分的数字,但是实数类型不只是用于存储小数,例如可以使用 DECIMAL 存储比 BIGINT 还大的整数。MySQL 支持精确类型和不精确类型。
FLOAT 使用 4 个字节,DOUBLE 使用 8 个字节,DECIMAL 允许最多 65 个数字(例如 DECIMAIL())。
字符串类型
- VARCHAR:用于存储可变长字符串,越短的字符串使用越少的空间,比 CHAR 更省空间,但需要使用额外的 1 个或 2 个额外字节记录字符串的长度。
- CHAR:用于存储定长的字符串,当存储 CHAR 值时,MySQL 会删除所有的末尾空格。(最好的策略是只分配真正需要的空间。)
- BLOB 和 TEXT:二者都是为了存储很大的数据而设计的字符串数据类型,分别采用二进制和字符方式存储。在对这两种字符串类型排序时,MySQL 只对在最前的 max_sort_length 字节进行排序。
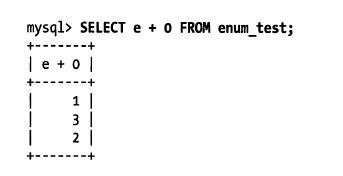
有时候可以使用枚举列代替常用的字符串类型。枚举列可以把一些不重复的字符串存储成一个预定义的集合。MySQL 在存储枚举时非常紧凑,会根据列表值的数量压缩到一个或者两个字节中。MySQL在内部会将每个值在列表中的位置保存为整数,并且在表的.frm文件中保存“数字-字符串”映射关系的“查找表”。

这三行数据实际存储为整数,而不是字符串。如果使用数字作为ENUM枚举常量,这种双重性很容易导致混乱,应该尽量避免这么做。 另外值得注意的是,枚举字段是按照内部存储的整数而不是定义的字符串进行排序的。
日期和时间类型
MySQL 能存储的最小时间粒度为秒(MariaDB 支持微秒),如果需要更小粒度的时间,可以使用 BIGINT 存储微秒级别的时间戳,或用 DOUBLE 存储秒之后的小数部分。
- DATETIME:能存储 1001 年到 9999 年范围的时间,精度为秒,使用 8 个字节的存储空间。
- TIMESTAMP:保存了从格林威治时间 1970 年 01 月 01 日 00 时 00 分 00 秒以来的秒数,与 UNIX 时间戳相同,使用 4 个字节的存储空间。
位数据类型
位数据类型底层都为字符串类型。
- BIT:最大长度为 64 个位,MySQL 将 BIT 当作字符串类型,而不是数字类型。
- SET:以一系列打包的位的集合表示。
选择标识符
完全随机的字符串,如 UUID、MD5 等,由于索引的原因,会导致 INSERT 和 SELECT 语句变得很慢。 对于 UUID ,应该移除 “-”符号,或者用 UNHEX() 函数转换为 16 字节的数字,并存储在 BINARY(16) 的列中,查找时可以通过 HEX() 函数来格式化为 16 进制格式。
特殊类型数据
如 IPv4 地址,一般会使用 VARCHAR(15) 来存储 IP 地址,但 IP 地址实际上是 32 位的无符号整数,不是字符串,所以应该用 UNSIGNINT 来存储 IP 地址。MySQL 提供了 INET_ATON() 和 INET_NTOA() 函数在这两种表示方法之间进行转换。
范式
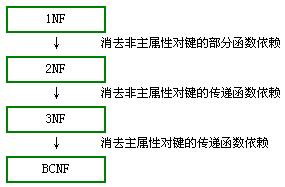
1NF:无重复的列,表中的每一列都是不可分割的基本数据项,任何关系型数据库都满足 1NF。
2NF:在 1NF 基础上,除了主键之外的其他列,都依赖于该主键,则满足 2NF。(消除部分子函数依赖 )
3NF:在 2NF 基础上,表中的列都和主键直接相关,而不能传递依赖,即不能是:非主键 A 依赖于非主键 B,非主键 B 依赖于主键。(消除传递依赖)
BCNF:在 3NF 基础上,表中不存在任何字段对任一候选关键字段的传递函数。
优点:
- 范式化的 UPDATE 操作通常比反范式化要快。
- 当数据较好地范式化时,就只有很少或者没有重复数据,修改的数据量更少。
- 范式化的表通常更小,执行操作会更快。
缺点:
- 范式化的 schema 通常需要关联,稍微复杂一些的查询语句在符合范式的 schema 上都可能需要至少一次会更多的关联,会影响查询性能。
反范式
反范式化指的是通过增加冗余或重复的数据来提高数据库的读性能,例如将所有数据都存在一张表中,可以很好地避免关联。
优点:
- 减少表的关联。
- 可以更好地进行索引优化,查询性能更高。
缺点:
- 表内冗余数据较多。
- 修改数据需要更多成本。
综上,在设计数据库时,要注意混用范式化和反范式化。
索引
索引在 MySQL 中也叫做键(Key),是存储引擎用于快速找到记录的一种数据结构,这是索引的基本功能。
索引基础
索引可以包含一个或多个列的值,如果索引包含多个列,那么列的顺序也十分重要,因为 MySQL 只能高效地使用索引的最左前缀列。
B-Tree 索引
B-Tree 索引使用 B-Tree 作为底层的数据结构,InnoDB 使用的是 B+Tree。
不同的存储引擎会以不同的方式使用 B-Tree 索引,性能也各有不同。例如 MyISAM 使用前缀压缩技术使索引更小,并通过数据的物理位置引用被索引的行,但 InnoDB 则按照原数据格式进行存储,并根据主键引用被索引的行。
B-Tree 意味着所有的值都是按顺序存储的,且每个叶子到根的距离相同。
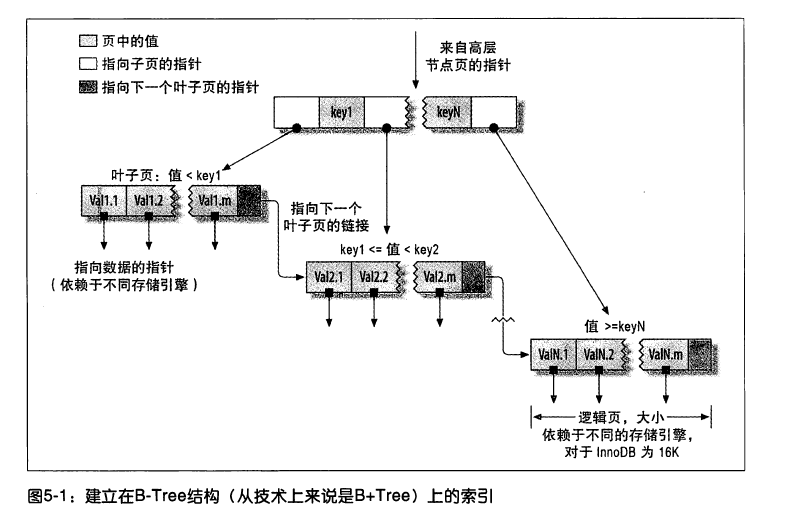
B-Tree 索引的键前缀查找只适用于最左前缀查找。
Hash 索引
Hash 索引基于哈希表实现,对于每一行数据,存储引擎会对所有的索引列计算 hash code。Hash 索引将所有的哈希码都存储在索引中,同时在哈希表中保存指向每个数据行的指针。
索引优点
- 索引大大减少了服务器需要扫描的数据量。
- 索引可以帮助服务器避免排序和临时表。
- 索引可以将随机 I/O 变为顺序 I/O。
MySQL 索引类型
INDEX:最基本的索引,没有任何限制。
UNIQUE:唯一索引,不允许重复,可以为 null。
PRIMARY:主键索引,是一种特殊的唯一索引,不允许为 null。
FULLTEXT: 表示全文搜索的索引。
高效的索引策略
- 使用独立的列,“独立的列”指的是索引列不能是表达式的一部分,也不能是函数的参数。
- 对于 TEXT 或很长的 VARHCAR 类型列,必须使用前缀索引,MySQL 不允许索引这些列的完整长度。
- 不要为每个列都创建索引。
- 在多列索引中选择合适的顺序。
- 使用覆盖索引,覆盖索引指的是包含所有需要查询字段的值得索引。
查询性能优化
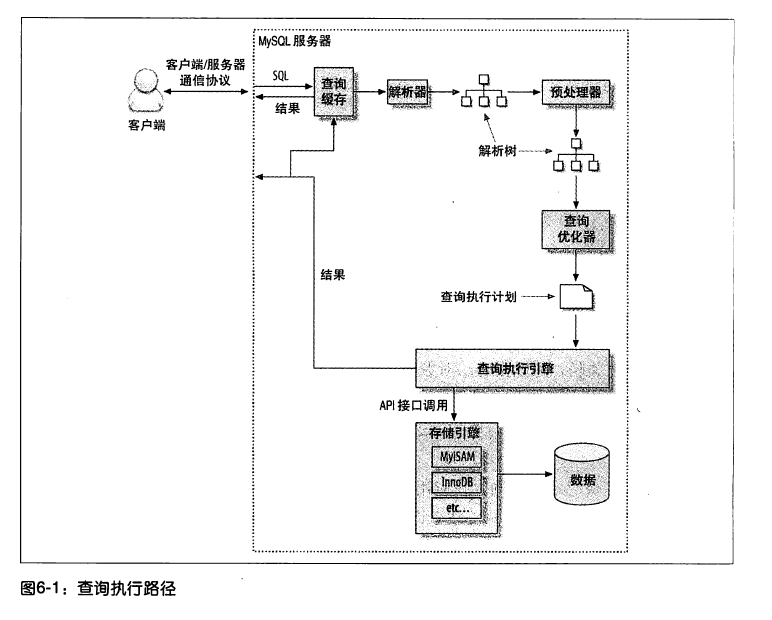
当用户向 MySQL 发送一个查询请求时,具体的执行过程如下:
- 客户端发送一条查询给 MySQL 服务器。
- 服务器检查缓存,如果缓存命中则立即返回缓存结果,否则进入下一步。
- 服务器端进行 SQL 解析、预处理,再由优化器生成对应的执行计划。
- MySQL 根据优化器生成的执行计划,调用存储引擎的 API 来执行查询。
- 将查询结果返回给客户端。
对于低效的查询,往往可以由以下两个原因导致:
- 应用程序请求了大量超过需要的数据。
- MySQL 服务器层正在分析大量超过需要的数据行。
对于 MySQL ,最简单的衡量查询开销的三个指标如下:
- 响应时间
- 扫描的行数
- 返回的行数
重构查询的方式
- 考虑是采用一个复杂查询还是多个简单查询。
- 用分治的思想进行分切查询,例如在删除大量数据时,分批量操作就是一个很好的例子。
- 分解关联查询。